ch3-3 外部妥当性・セグメント・解釈の罠
前節までで扱った内的妥当性は、「この実験の内側で因果解釈が筋が通っているか」を問うものだった。この節の主題はその先にある三つである。第一は 外部妥当性(external validity) 、すなわち「ここで得た結果を、他の集団や別の期間へどこまで一般化してよいか」である。第二は セグメント分析 、すなわち「全体平均では見えない、集団ごとの違いをどう読むか」である。そして第三は、セグメントを切ったり期間や割合をまたいで集計したりするときに待ち構える 解釈の罠 (シンプソンのパラドックスなど)である。
これらはいずれも、 「全体平均が正しくても、一般化や分割の仕方を誤ると結論が反転する」 という共通の難所を抱えている。本節を通じて身につけたいのは、時間方向の効果の変化を疑う視点と、セグメントを賢く使いつつその落とし穴を避ける規律である。
外部妥当性の扱い
外部妥当性 とは、コントロール実験の結果が、 異なる人々の集団 (他の国、他の Web サイトなど)や 異なる期間 (たとえば「2% の収益増は長く続くのか、それとも減衰するのか」)といった軸に沿って、どの程度一般化できるかを指す。
まず、 異なる集団への一般化は、たいてい疑わしい 。あるサイトで効く機能が別のサイトで効くとは限らない。ただし、この問題への対処は比較的単純である。米国で成功した実験について「結果はそのまま一般化する」と仮定するのではなく、 他の市場でも実験して確かめればよい のである。
次に、 異なる期間への一般化は、より厄介である 。長期的な効果を見るために、実験を何か月も走らせたままにすることもある(Hohnhold, O’Brien and Tang 2015)。長期効果への対処は第 19 章で扱うが、時間方向の外部妥当性を脅かす重要な二つの現象が プライマシー効果 と ノベルティ効果 である。
プライマシー効果
プライマシー効果(primacy effect) とは、 変更直後はユーザーが古い仕様に慣れているために、新機能の採用に時間がかかる 現象である。最初は効果が出にくく、ユーザーが慣れるにつれて徐々に効果が立ち上がる。加えて、機械学習アルゴリズムの場合、より良いモデルを学習できるとしても、 モデルの更新サイクル次第では、その効果が出揃うまでに時間がかかる 。
ノベルティ効果
ノベルティ効果(novelty effect、新規性効果) は、 持続しない効果 のことである。新しい機能、とりわけ目を引く機能を導入すると、最初はユーザーが珍しさにつられて試す。しかし、その機能に本当の有用性がなければ、リピート利用は伸びない。結果として、 導入直後はうまくいっているように見えても、時間が経つと効果が急速にしぼむ 。
ノベルティ効果の好例が、『Yes!: 50 Scientifically Proven Ways to Be Persuasive』(Goldstein, Martin and Cialdini 2008)に出てくる逸話である。Colleen Szot は、20 年間破られなかったホームショッピング番組の販売記録を、 決まり文句のたった 3 語を変えるだけ で塗り替えた。おなじみの「オペレーターが待機しています、今すぐお電話ください(Operators are waiting, please call now)」を、「オペレーターが混雑している場合は、もう一度お電話ください(If operators are busy, please call again)」に変えたのである。これは 社会的証明(social proof) の働きだと説明される。視聴者は「電話がつながりにくいなら、自分と同じようにこの番組を見て電話している人が大勢いるのだろう」と考えたわけである。ただし、こうした仕掛けは、 常用されているとユーザーに気づかれると有効期間が短くなる 。コントロール実験で見れば、分析するそばから効果が薄れていく典型例である。
別の例を見る。MSN の Web サイトのトップには、図 3.2 のようなストライプ(リンク帯)があった(Dmitriev et al. 2017)。
Microsoft はこの Outlook.com のリンクとアイコンを変更し、クリックすると Outlook メールアプリを直接開く ようにした(図 3.3)。
予想どおり、介入群では対照群よりも多くのユーザーがメールアプリを使った。ところが予想外だったのは、 CTR(クリック率)が +28% という非常に大きな増加 を示したことである。「ユーザーはメールアプリを気に入って、より頻繁に使うようになったのか」と解釈したくなる。しかし調査の結果、真相はまったく逆だった。 ユーザーは Outlook.com が(ブラウザで)開かないことに戸惑い、リンクを何度も繰り返しクリックしていた のである。つまり +28% は満足ではなく混乱の表れであり、典型的なノベルティ(というより一時的な戸惑い)由来の見かけ上の増加だった。
さらに極端な例として、中国のスニーカーメーカー Kaiwei Ni は、図 3.4 のように 携帯画面に偽の抜け毛を表示する Instagram 広告 を出した。ユーザーは画面の「髪の毛」を払いのけようとスワイプし、その動作で誤って広告をクリックさせられた。ここではノベルティ効果(の悪用)が大きかったと思われる。なお、この広告は Instagram から削除されただけでなく、アカウントも無効化された(Tiffany 2017)。

プライマシー効果・ノベルティ効果の検出
これらを見抜く最も重要な手立ては、 介入効果を時間方向にプロットし、増減を観察する ことである。先の MSN の例では、図 3.5 のように、メールリンクをクリックするユーザーの割合が時間とともに明らかに減少していた。
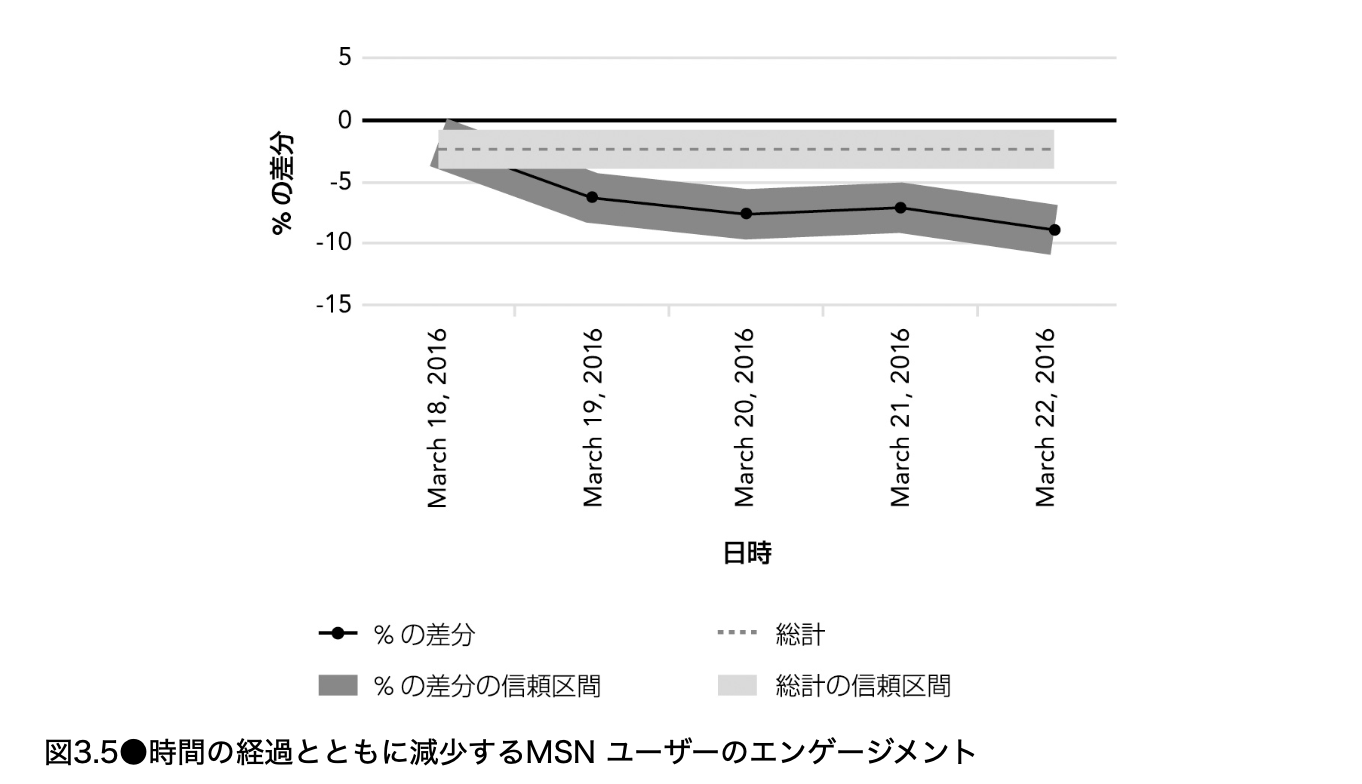
標準的な実験分析では、 介入効果はどの時点でも一定 だと仮定している。しかし図 3.5 のような傾向は、その仮定が破れている 危険信号 である。こうした実験では、 効果がいつ安定するかを見極めるために、より長く走らせる必要がある 。そして、この例が示すように、長く回すことで「このアイデアは悪い」と十分に結論づけられることも多い。ただし、実験を長期化させるアプローチ自体にも注意が必要である(第 23 章参照)。
プライマシー効果・ノベルティ効果が疑われるときの追加の手段として、 最初の 1〜2 日に登場したユーザーだけに着目し、そのコホートに対する介入効果の時間変化をプロットする 方法がある。同じユーザー集団を時間方向に追うことで、効果が立ち上がるのか減衰するのかが際立つ。
Hulu での具体例 :ホーム画面に派手な新演出(たとえば大きな自動再生プレビューや「NEW」バッジ)を加えると、初週は物珍しさで再生開始やクリックが跳ね上がりやすい。しかしノベルティ効果なら、数週間で元の水準へ戻る。逆に、新しい推薦モデルは、ユーザーの新しい行動ログがたまり、モデルが再学習されるまで真価を発揮しないことがあり、これはプライマシー効果として現れる。したがって、 新ランキングは初週の数字だけで判断せず、効果曲線が平坦になるまで観察し、できれば「初日コホート」を追跡する べきである。25% 以上視聴やリピート視聴といった、一時的な好奇心では動きにくい指標を併用することも有効である。
セグメントの違い
セグメントごとにメトリクスを分析すると、全体平均では見えない洞察が得られ、欠陥の発見や次の実験のアイデアにつながる。ただし、後述するようにトワイマンの法則と多重比較を意識する必要がある。良いセグメントの例を挙げる。
市場・国 :ある国で効いた機能が別の国で効かないとき、原因は翻訳の不備、すなわちローカライゼーションの問題であることがある。
デバイス・プラットフォーム :ブラウザかデスクトップか携帯か。モバイルなら iOS か Android か。ブラウザのバージョン差で JavaScript のバグや非互換が露見することがある。携帯ではメーカー(Samsung、Motorola など)独自のアドオンが不具合を生むことがある。
時間帯・曜日 :効果を時間方向に描くと興味深いパターンが見える。週末のユーザーは平日のユーザーと多くの特徴で異なり得る。
ユーザーのタイプ :新規か既存か。新規とは、ある基準日(実験開始時や 1 か月前など)以降に参加したユーザーを指す。
アカウントの特徴 :Netflix のシングル/シェアアカウント、Airbnb の独身/家族旅行者などの違い。
セグメントビューの使い方は、大きく二通りある。
実験に依存しないメトリクスのセグメントビュー (後述の「メトリクスのセグメントビュー」)。
介入効果のセグメントビュー 。統計学で ヘテロジニアス(heterogeneous、異質) と呼ばれる、 介入効果がセグメント間で均一でない ことを示すもの。
メトリクスのセグメントビュー
Bing のモバイル広告の CTR をモバイル OS 別に見ると、図 3.6 のように大きく異なっていた。
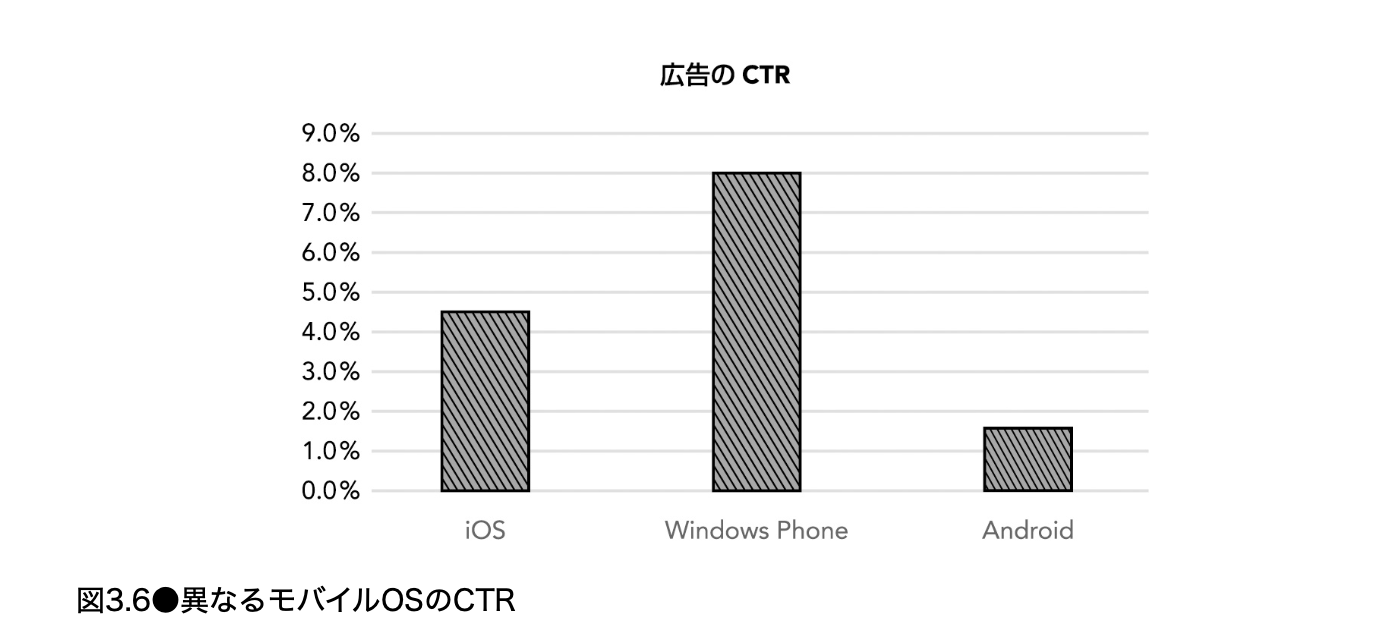
当初は「OS ごとにユーザーのロイヤルティや母集団が違うのだろう」というストーリーを描きたくなった。しかし調査の結果、違いの正体は クリックトラッキングの方法差 だった。計測法によって精度が異なる(Kohavi, Messner et al. 2010)。iOS と Windows Phone はクリック計測にリダイレクトを使っており、精度は高いがユーザー体験に影響する。Android は Web ビーコンを使い、ブラウザは目的ページへ素早く遷移するが、 一部のビーコンが間に合わず欠損が大きい 。これで iOS と Android の CTR 差は説明できる。
では、なぜ Windows Phone の CTR はこれほど高かったのか。さらに調べると、リダイレクトに加えて、 ユーザーのスワイプが誤ってクリックとして記録されるバグ があった。バグは起こり得るものなので、 異常なデータを見たら、トワイマンの法則を念頭に原因を調査すべき である。
Hulu での具体例 :再生開始率や CTR をデバイス別(iOS / Android / TV アプリ / Web)に切ると、しばしば大きな差が出る。しかしその差は、視聴意欲の本質的な違いではなく、 各プラットフォームでイベント送信の実装やビーコンの欠損率が違うこと に由来する場合がある。OS 別の差を見たら「ユーザー特性の物語」を作る前に、まず計測経路の違いを疑うのが堅実である。
介入効果のセグメントビュー(ヘテロジニアスな介入効果)
ある実験で UI を変更したところ、 ブラウザセグメント間で非常に強い差 が出た。ほぼすべてのブラウザで介入効果は主要メトリクスにわずかな正の改善だったのに、 Internet Explorer 7 のセグメントだけは強い負の効果 を示した。強い効果(正でも負でも)が出たら、ここでもトワイマンの法則を発動して原因を掘り下げる。調査の結果、使っていた JavaScript が IE7 と非互換で、特定の状況でリンクをクリックできないエラーが起きていたと判明した。
このような洞察は、 セグメントへのドリルダウンを行ってこそ 得られる。セグメントごとに異なる介入効果は、統計学で 条件付き平均介入効果(CATE、Conditional Average Treatment Effects) と呼ばれる(ヘテロジニアスな介入効果の概観は EGAP 2018 が詳しい)。興味深いセグメントの特定や交互作用の探索には、決定木(Athey and Imbens 2016)やランダムフォレスト(Wager and Athey 2018)といった機械学習・統計手法も使える。
興味深いセグメントを実験者に自動で警告できれば、多くの洞察が得られる。ただし前述のとおり、 多数のセグメントを見ることは多重仮説検定なので、p 値の補正を忘れてはならない 。組織にとって A/B テストの実施は重要な一歩であり、全体の介入効果だけでなく、こうしたセグメントの情報まで提供することで、イノベーションを加速させる新しい洞察が得られる。
Hulu での具体例 :新ランキングの効果を「TV アプリ/モバイル/Web」「新規/既存」「特定ジャンルの視聴者」で切ると、ある特定の古い OS バージョンやデバイスだけで強い負の効果が出ることがある。これはたいてい、そのデバイスでの描画バグや、特定の作品メタデータの欠損が原因である。セグメント分析は、こうした「全体平均に埋もれた不具合」を掘り当てる強力な道具である。
セグメント別の介入効果分析はミスリードを起こし得る
セグメント分析は強力だが、 使い方を誤ると全体と矛盾する結論を導く 。相互に網羅的かつ排他的な二つのセグメントで OEC がともに増加したのに、全体では減少する、ということが起こり得るのである。これは(次節の)シンプソンのパラドックスとは別物で、 あるセグメントから別のセグメントへユーザーが移動すること が原因になる。
例として「1 ユーザーあたりのセッション数」を考える。ほとんどのユーザーが使っていない新機能 F に取り組んでいるとしよう。実験の結果、F を使っているユーザーの 1 人あたりセッション数は増えていた。着目指標が改善したので良い結果に見える。しかし、F を使っていない補完的なユーザーに目を移すと、そちらでも 1 人あたりセッション数は減っていない(横ばいか増加)かもしれない。
この一見不可解な現象は、 ユーザーがセグメント間を移動する ことで説明できる。F を使うユーザーは 1 人平均 20 セッション、使わないユーザーは平均 10 セッションだとする。ここで、 介入によって「セッション数 15 のユーザー」が F の利用をやめた とどうなるか。
ワークド例:両セグメントとも平均が上がるのに、全体は変わらない
具体的な小さな数値で確かめる。対照群と介入群を比べる形で書く。
対照群(介入なし)のセグメント構成を次とする。
| セグメント | ユーザーのセッション数 | 平均 |
|---|---|---|
| F 利用 | ||
| F 非利用 | ||
| 全体 | 上記 7 名 合計 |
介入群では、機能 F の変更により、 セッション数 15 のユーザーが F の利用をやめて「F 非利用」へ移動 したとする。すると構成は次になる。
| セグメント | ユーザーのセッション数 | 平均 |
|---|---|---|
| F 利用 | ||
| F 非利用 | ||
| 全体 | 上記 7 名 合計 |
結果を比べると、 F 利用セグメントの平均は 18.75 から 20.0 へ上昇 し、 F 非利用セグメントの平均も 10.0 から 11.25 へ上昇 している。両方のセグメントで平均セッション数が増えたのである。ところが、 全体の合計セッション数も人数も変わっていない(105 / 7 = 15.0)ので、全体平均はまったく改善していない 。
からくりはこうである。F 利用セグメントからは「平均より低い 15」のユーザーが抜けたため、残った人の平均が押し上がる。一方、F 非利用セグメントには「もとの平均より高い 15」のユーザーが加わったため、こちらの平均も押し上がる。どちらの平均も上がるが、それは中身の入れ替えによる見かけであり、価値が増えたわけではない。条件次第で、全体のセッション数は上昇・下降・横ばいのいずれにもなり得る(Dmitriev et al. 2016, section 5.8)。
したがって、 ユーザーがセグメント間を移動するときは、セグメント別メトリクスの変化の解釈はミスリードになり得るので、セグメント化していない全体のメトリクスで介入効果を判断する 必要がある。理想は、 実験前に確定した値だけでセグメントを定義し、介入によってセグメントが変わらないようにする ことである。ただし実務では、実験の狙い次第でこの制約が難しいこともある。
Hulu での具体例 :「特定の新しい棚 F を使ったユーザー」と「使わなかったユーザー」で視聴時間を比べるのは危うい。なぜなら、棚 F を使うかどうかは介入後の行動で決まり、 介入によってユーザーが二つのセグメント間を移動する からである。たとえば、ライトユーザーが新しい棚に流れて「F 利用」側に移れば、F 利用側の平均は下がり、F 非利用側(ヘビーユーザーが残る)の平均は上がる、という見かけが生じる。判断は、 割当時点で固定された属性(実験前の視聴量など)で切るか、セグメント化しない全体の介入効果で行う べきである。
シンプソンのパラドックス
ここからは Crook et al.(2009)に基づく。実験を 段階的に拡大 していくとき(第 15 章参照)、つまり介入群に割り当てる割合が途中で二つ以上の異なる値をとったとき、各段階を 単純に合算すると介入効果の推定を誤る ことがある。各段階では介入群が対照群より優れているのに、合算すると全体では劣って見える、という直観に反する現象であり、 シンプソンのパラドックス(Simpson’s paradox) と呼ばれる(Simpson 1951 ほか)。
表 3.1 に簡単な例を示す。あるサイトは金曜・土曜の 2 日間、各日 100 万人の訪問者がある。金曜はトラフィックの 1% を介入群に割り当て、土曜はその割合を 50% に引き上げた。
表 3.1 ●2 日間のコンバージョン率。各日の顧客数は 100 万人であり、各日の介入(T)はコントロール(C)より優れているが、全体では悪化している
| 金曜日 | 土曜日 | 総計 | |
|---|---|---|---|
| C | |||
| T |
金曜は T(2.30%)が C(2.02%)より良く、土曜も T(1.20%)が C(1.00%)より良い。 どちらの日も介入群が勝っている 。それなのに、2 日分を単純に足し合わせると、 総計では T(1.20%)が C(1.68%)に負けて見える 。
上の数学に誤りはない。 数学的には が成り立ち得る 。腑に落ちにくいのは、これが 加重平均 だからである。介入群の利用者は、コンバージョン率の低い土曜に大きく偏っている(金曜 1 万人に対し土曜 50 万人)。その結果、介入群の総計平均は「悪い土曜」に強く引っ張られ、1.20% まで下がってしまう。一方、対照群は金曜に 99 万人と大半がいるため、「良い金曜」の重みが大きく、総計は 1.68% と高くなる。 同じ介入効果でも、群ごとに「どの日に重みが乗っているか」が違えば、合算結果は逆転し得る のである。
コントロール実験でシンプソンのパラドックスが起こり得る他の状況も挙げる。
ユーザーがサンプリングされている場合 :全ブラウザの代表サンプルを得るため、サンプリングが一様でなく、一部のブラウザ(Opera や Firefox など)が高い割合で抽出されることがある。全体では介入群が良く見えても、ブラウザ別に切ると全ブラウザで介入群が悪い、ということがあり得る。
国ごとに割合が異なる場合 :米国とカナダで動く実験で、米国は介入群 1%、カナダは検出力計算の結果 50% 必要と判断、というように国で割合が違う。国で分割されているのに結果を結合すると、介入群が優れて見えて実は劣っている、ということが起こる。これは前述の「実験拡大に伴う比率変更」と直接対応する。
最重要顧客だけ参加率を下げた場合 :基本は 50:50 だが、支出上位 1% の最重要顧客は安定性を懸念して 1% だけ実験に入れる、とビジネス側を説得したとする。すると、全体は肯定的でも、最重要顧客とそれ以外の両方で悪化している、ということがあり得る。
データセンターごとに別々にアップグレードした場合 :DC1 の顧客向けにバージョンアップして満足度が上がり、DC2 でも 2 回目のアップグレードで満足度が上がった。それでも、集計データを見る監査人には、全体の満足度が下がって見えることがある。
シンプソンのパラドックスは直観に反するが、珍しくはない。実際の実験で何度も観測されている(Xu, Chen and Fernandez et al. 2015、Kohavi and Longbotham 2010)。 異なる割合で集めたデータを集約するときは要注意である 。
最後に、因果の観点を述べる。シンプソンのパラドックスは一見、「ある薬が男性でも女性でも回復確率を下げる(有害)のに、全体では回復確率を上げる」という数学的可能性を示しているように見える。これは「性別不明なら飲むべきだが、男女いずれと分かれば避けるべき」という不合理を含意するように見える。Pearl(2009)は、 観察データだけ(集団全体を使うか部分集団を使うか)ではこのパラドックスを解決できず、因果モデルが必要 であることを示した。Sure Thing Principle(Pearl 2009 の定理 6.1.1)は、 ある行動が各部分集団で事象 E の確率を増やすなら、母集団全体でも E の確率を増やすことを要求する 。つまり、現実の因果としては「全部分集団で良いのに全体で悪い」は成立せず、表 3.1 のような逆転は、 割当割合という人為的な重みの偏りが生んだ見かけ にすぎないのである。
Hulu での具体例 :新ランキングを段階的にロールアウトし、第 1 週は 1%、第 2 週は 50% に拡大したとする。各週では介入群の 25% 以上視聴率が対照群を上回っていても、2 週を単純合算すると、週ごとの基準視聴率の違い(たとえば新作配信のあった週とない週)と割当割合の偏りが絡んで、全体では介入群が劣って見えることがある。対策は、 割合が変わった期間をまたいで単純合算せず、期間ごとに分けて分析する か、割当割合の差を考慮した適切な集計(層別の加重)を行うことである。
健全な懐疑主義の奨励
SumAll での共同 A/B テストの取り組みを始めて半年が経ったが、私たちは不快な結論に達していた。勝利した結果のほとんどは顧客獲得につながらなかった……私たちは横道にそれていたのだ。
— Peter Borden (2014)
信用できる実験に投資することは、組織にとって難しい場合がある。なぜなら、「テストに失敗したら結果を無効にするテスト」という、一見すると後ろ向きに見える仕組みに投資することになるからである。しかし、優秀なデータサイエンティストは 懐疑主義者 である。彼らは異常を調べ、結果に疑問を持ち、 結果が良すぎると感じたらトワイマンの法則を発動する 。
本節の内容は、まさにこの懐疑主義を具体的な技術に落とし込んだものである。外部妥当性では「初週の数字を鵜呑みにせず、効果曲線とコホートで時間変化を疑う」。セグメントでは「全体に埋もれた異常を掘り出しつつ、多重比較とセグメント移動の罠を避ける」。そして集計では「割合が変わったデータの単純合算を疑い、シンプソンのパラドックスを念頭に置く」。Hulu の推薦実験でも、 驚くほど良い結果ほど立ち止まって検算し、時間・セグメント・集計の三方向から健全に疑う ことが、信用できる意思決定への近道である。