ch1-1 動機と用語の詳解:Bing 事例から 推薦 A/B テストへ
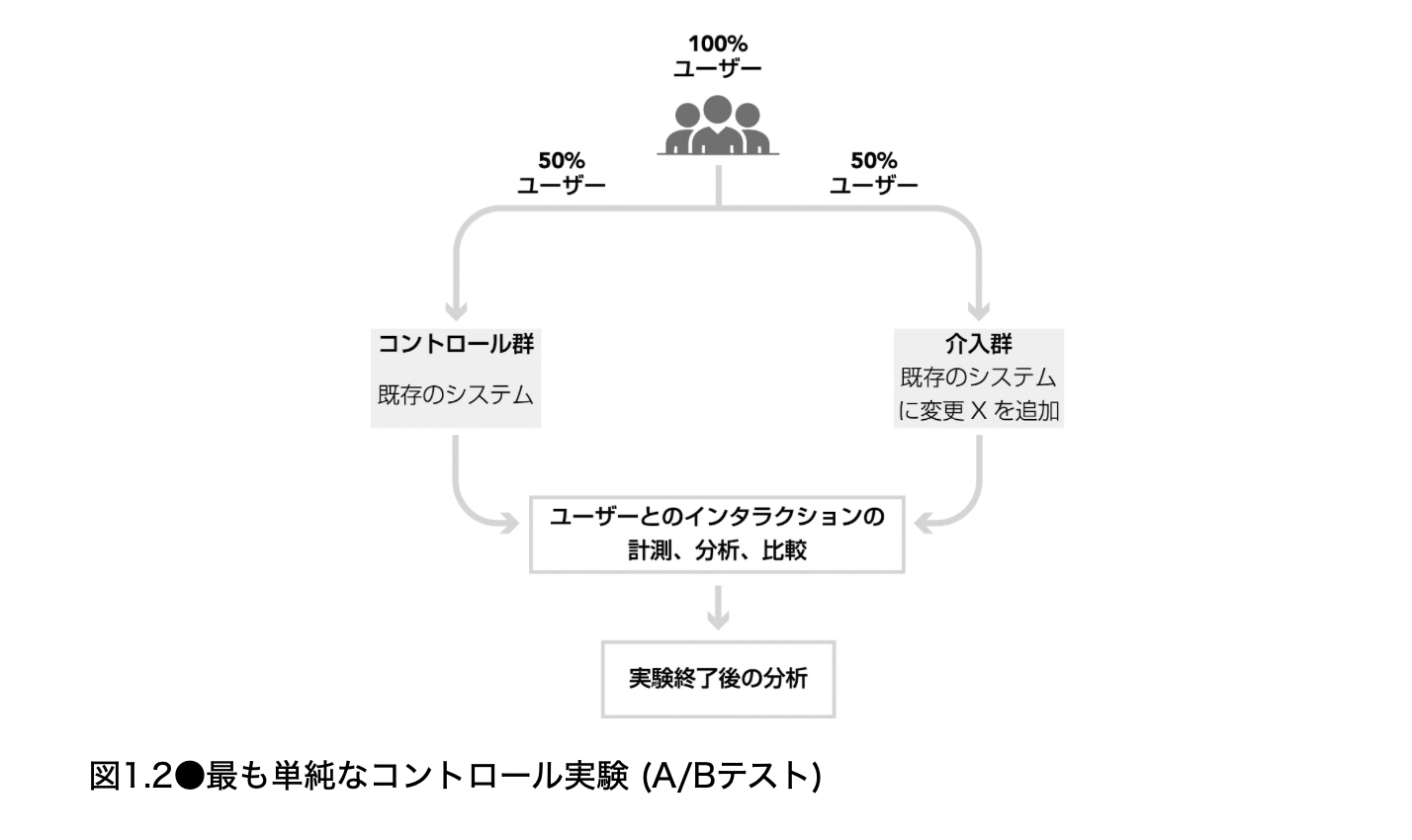
この節で最も重要なメッセージは、「専門家の意見やチーム内の直感だけでは、ユーザー体験の変更が本当に良いかどうかは分からない」ということである。もちろん、専門家の知識は無価値ではない。むしろ、良い仮説を作るためには、プロダクト理解、ユーザー理解、ML モデルの理解、ログ仕様の理解が不可欠である。しかし、ある変更が実際のユーザー行動を改善するかどうかは、最終的には実ユーザーを対象にした測定によって確かめる必要がある。
Hulu の動画推薦で考えると、これはかなり自然な話である。例えば、オフライン評価で Recall@K や NDCG@K が改善した新しい推薦モデルがあったとしても、そのモデルを実際にプロダクトへ出したときに、ユーザーがより多く視聴するとは限らない。なぜなら、オフライン評価は過去ログ上の当てやすさを測っているだけであり、推薦面の見え方、作品サムネイル、デバイス、時間帯、作品の公開終了日、ユーザーの気分、既に視聴済みかどうか、といった現実の利用文脈を完全には再現できないからである。
したがって、この節は単に「A/B テストは便利である」と言っているのではない。より正確には、「プロダクト変更の価値は人間の予想を大きく外れることがあるため、ユーザーをランダムに分け、同時期に、同じ測定基盤で、変更の因果効果を推定できる仕組みを持つべきである」と述べているのである。
Bing の広告タイトル変更の事例で何が起きたのか
教科書の Bing の例では、広告タイトル行を、その下の 1 行目のテキストと組み合わせて長く表示するという変更が提案された。この変更は、実装としては小さく、当初は優先順位も低かった。つまり、チームの直感としては「重要そうな大規模施策」ではなかったのである。

しかし、ある開発者がこの変更を実装し、一部のユーザーには従来の表示を出し、別の一部のユーザーには新しい表示を出した。これが A/B テストである。重要なのは、ユーザーがランダムに分けられていたことである。ランダム化によって、介入群とコントロール群のユーザー構成は、平均的には同じような分布になる。したがって、両群の差は、広告タイトル表示の変更によって生じた可能性が高いと解釈できる。
テスト開始後、Bing では収益が非常に大きく上がったため、アラートが発火した。ここで面白いのは、良い結果が出たからといってすぐに喜んだわけではない点である。あまりにも良すぎる結果は、しばしば計測バグや実装バグを示す。例えば、広告収益が二重に記録されている、広告だけが表示されてページの他の部分が壊れている、クリックイベントが重複送信されている、といった可能性がある。
Hulu の推薦でも同じである。例えば、新しい推薦モデルの Treatment で「25% 以上視聴されたシリーズ数」が急に 30% 増えたとする。この数字だけを見ると大成功に見える。しかし、実際には次のような問題かもしれない。
視聴イベントが重複して
unique_viewed_series相当の集計に入っている。自動再生の挙動が変わり、ユーザーの明確な選択ではない視聴が増えている。
Treatment だけ人気作品や新着作品を過剰に出しており、短期視聴は増えたが作品探索の多様性が落ちている。
一部デバイスで推薦 UI が崩れ、特定の行だけが押されやすくなっている。
実験割当やログ結合に不具合があり、Control と Treatment の母集団がそもそも比較可能でない。
したがって、Bing の事例から学ぶべきことは「小さな変更でも大きな改善があり得る」だけではない。それに加えて、「大きすぎる改善は、まず測定と実装を疑って検証する必要がある」という運用上の姿勢も重要である。
なぜ専門家の意見だけでは足りないのか
専門家の意見には限界がある。なぜなら、オンラインプロダクトでは、ユーザー行動が多くの要因によって同時に変化するからである。動画推薦であれば、作品の公開開始や公開終了、季節性、曜日、キャンペーン、アニメ新シーズンの開始、話題作の追加、アプリの性能、UI の変更、通知施策などが、視聴行動に影響する。
例えば、ある週に Hulu のトップページ推薦を新モデルへ切り替え、その週の視聴数が前週より増えたとする。このとき、「新モデルのおかげで増えた」とはまだ言えない。なぜなら、その週に人気アニメの新シーズンが公開されたかもしれないし、連休で全体視聴時間が増えたかもしれないし、マーケティング施策で休眠ユーザーが戻ってきたかもしれないからである。
A/B テストは、この問題をかなりきれいに扱う。Control と Treatment を同じ期間に走らせ、ユーザーをランダムに割り当てることで、季節性やキャンペーンのような外部要因は、原則として両群に同じようにかかる。すると、両群の平均差を、変更による因果効果として解釈しやすくなる。
因果推論の言葉で言えば、本当に知りたいのは各ユーザー についての「Treatment を受けた場合の結果」と「Control を受けた場合の結果」の差である。しかし、同じユーザーに同じ時点で両方の体験をさせることはできない。そこで、ランダム化された集団平均の差を使って平均的な効果を推定する。
ここで、 は Treatment を受けた場合のアウトカム、 は Control を受けた場合のアウトカムである。実験では個々のユーザーの両方の値は観測できないが、ランダム化により次の差で近似できる。
Hulu の例では、 を「実験期間中に profile
が 25%
以上視聴したユニークシリーズ数」と置ける。これは
unique_viewed_series
の思想に近い暗黙的フィードバックである。
例えば、14 日間の実験で Control に 100,000 プロフィール、Treatment に 100,000 プロフィールが割り当てられたとする。そして、1 プロフィールあたりの 25% 以上視聴シリーズ数の平均が次のようになったとする。
Control:
Treatment:
このとき、絶対差は次のようになる。
相対リフトは次のようになる。
この結果は、「Treatment の推薦体験によって、実験期間中の 25% 以上視聴シリーズ数が平均で 1 プロフィールあたり 0.08 本増えた」と解釈できる。ただし、これは OEC やガードレールをどう定義したかに依存する。もし同時にアプリクラッシュ率、再生開始失敗率、解約率の短期 proxy、検索への逃避、同一人気作品への過集中などが悪化しているなら、単純に成功とは言えない。
Bing 事例が示す 5 つのテーマ
教科書は Bing の事例から、オンライン実験の重要なテーマを 5 つ挙げている。それぞれを Hulu の推薦開発に置き換えると、意味がかなり明確になる。
1. アイデアの価値を見積もることは難しい
Bing の広告タイトル変更は、事前には高い価値があると思われていなかった。にもかかわらず、結果的には非常に大きな収益改善を生んだ。これは、人間が事前にアイデアの価値を正確に順位付けするのが難しいことを示している。
Hulu の推薦でも同じである。例えば、次のような施策の価値を事前に正確に見積もるのは難しい。
avg_fingerprintのような動画内容 embedding を使って、視聴済み作品に雰囲気が近い作品を推薦候補に追加する。avg_mood_tagを使って、「感動的」「サスペンス」「知的」などの雰囲気が近い作品を混ぜる。シリーズ単位の視聴履歴に基づき、同じジャンルや同じ出演者の作品を少し強める。
推薦棚の 1 行目ではなく 2 行目に新しい候補生成ロジックを出す。
TVOD 作品を推薦に混ぜる比率を変える。
これらは、エンジニアや PM の直感だけでは勝ち負けを判断しにくい。オフライン指標で候補を絞ることはできるが、最終的には実際のユーザーがどう反応するかを見る必要がある。
2. 小さな変更が巨大な影響を与えることがある
Bing の例では、広告タイトルの表示を少し変えただけで収益が 12% 増えた。これはかなり極端な例であり、頻繁に起きるものではない。しかし、プロダクトでは「小さく見える変更」が、ユーザーの認知や行動のボトルネックを取り除くことがある。
Hulu で言えば、推薦モデルそのものを大きく変えなくても、次のような小さな変更が大きな影響を持つ可能性がある。
推薦棚のタイトルを「あなたにおすすめ」から「もう一度観たい名作と近い作品」に変える。
既視聴シリーズを推薦候補から除外する閾値を変える。
公開終了が近い作品を少しだけ上位に出す。
長尺映画と短尺エピソードを同じランキングで混ぜる際の正規化を変える。
子供向けプロフィールでは、過去に完走したシリーズの続編や関連作品を少し強める。
このような変更は、コード差分としては小さくても、ユーザーの「何を観るか決める」瞬間に効く場合がある。したがって、小さい変更だから実験しなくてよい、あるいは小さい変更だから価値がない、とは言えない。
3. 巨大な影響がある実験はまれである
一方で、Bing 級の大成功が頻繁に起きるわけではない。教科書が強調しているように、毎年大量の実験をしていても、非常に大きな改善は数年に一度ということがある。
これは実務上かなり重要である。つまり、A/B テストを数回やって大きな勝ちが出ないからといって、「実験には価値がない」と判断するのは早い。多くの実験は、小さな改善、小さな悪化、または不明瞭な結果になる。だが、その積み重ねによってプロダクトは改善される。また、負け実験にも価値がある。少なくとも、そのアイデアを全ユーザーへ出して悪化させることを避けられたからである。
推薦 ML では、オフラインで有望そうなモデルがオンラインで勝たないことは珍しくない。例えば、過去視聴に似た作品をより高精度に当てるモデルは、短期的なクリックや視聴開始を増やすかもしれない。しかし、ユーザーがすでに知っている作品ばかりを出してしまい、新しい発見を減らす可能性もある。逆に、やや多様性を増やしたモデルは、短期の 25% 視聴率では微妙でも、長期の継続や満足度に効く可能性がある。
このように、実験結果は常に分かりやすく勝ち負けが出るとは限らない。だからこそ、実験を継続的に回す文化と基盤が必要になる。
4. 実験開始までのオーバーヘッドは小さくなければならない
Bing の例では、エンジニアが簡単に実験を開始できる実験システムを使えたことが重要である。もし実験の開始に何週間もかかるなら、小さなアイデアは試されない。すると、組織は結局、偉い人の意見や大きなロードマップ施策だけに依存しやすくなる。
Hulu の推薦開発でも、実験開始のオーバーヘッドが大きいと、次のような問題が起きる。
新しい候補生成ロジックを少し試したいだけなのに、割当、ログ、集計、ダッシュボードの準備が重すぎて試せない。
オフライン評価で良さそうなモデルが複数あっても、オンラインで比較できる数が限られる。
実験設定が属人化し、分析者によって母集団や指標定義がずれる。
結果確認に時間がかかり、次の改善サイクルが遅くなる。
理想的には、推薦チームは次のような標準化された実験基盤を持つべきである。
profile_idなどの安定したキーに基づく永続的な実験割当。Treatment ごとの推薦露出ログ、クリック、再生開始、25% 以上視聴、完走、離脱などのイベントログ。
SRM、ログ欠損、イベント重複、極端なメトリクス変化を検知するアラート。
OEC とガードレールを同じ定義で見るダッシュボード。
小さく開始し、問題がなければ段階的にランプアップする仕組み。
この基盤があると、チームは「議論で決める」だけではなく、「仮説を素早く実験で確かめる」方向へ進める。
5. OEC が明確でなければならない
OEC は Overall Evaluation Criterion の略であり、実験の目的を定量化した総合評価基準である。簡単に言えば、「この実験は何が良くなったら成功なのか」を表す中心指標である。
Bing の例では、収益が大きく増えた。しかし、収益だけを OEC にすると危険である。なぜなら、ユーザー体験を悪化させる広告を増やせば、短期収益だけは上がるかもしれないからである。短期収益を最大化するだけなら、広告を目立たせすぎる、広告を増やしすぎる、誤クリックを誘う、といった悪い方向にも進めてしまう。
Hulu の推薦でも同じ問題がある。例えば、OEC を「再生開始数」だけにすると、サムネイルやタイトルで強く引き付ける作品、短尺で再生しやすい作品、既に人気の作品に偏るかもしれない。しかし、再生開始後すぐ離脱するなら満足度は低い可能性がある。また、特定の人気作品ばかり推薦して一時的な視聴は増えても、ユーザーの発見体験やカタログ消費の健全性を損なう可能性がある。
したがって、Hulu の推薦における OEC
は、暗黙的フィードバックを使いつつも、単純なクリックや再生開始だけにしない方がよい。unique_viewed_series
では、コンテンツ長の 25%
以上視聴したシリーズが記録されるため、「単に押した」よりも強い興味シグナルとして使える。これは
OEC の候補になり得る。
ただし、25% 以上視聴シリーズ数だけでも万能ではない。例えば、短いエピソードと長い映画では 25% の意味が違う。また、ユーザーが本当に満足したかどうかは 25% 視聴だけでは分からない。さらに、ある推薦が短期的な視聴数を増やしても、長期的な継続率や解約率にどう効くかは別問題である。
そのため、現実的には OEC とガードレールを分けて考えるとよい。
OEC: 実験で最も改善したい中心指標。例として、1 プロフィールあたりの 25% 以上視聴ユニークシリーズ数、推薦経由の 25% 以上視聴率、視聴日数、一定以上の視聴時間などがある。
ガードレール: 改善してはいけない、または悪化してはいけない安全指標。例として、再生開始失敗率、アプリクラッシュ率、レイテンシ、短時間離脱率、検索への逃避、解約 proxy、キッズプロフィールでの不適切推薦率、TVOD への過度な誘導などがある。
教科書は「単一のメトリクスを選ぶことが望ましい」と述べている。ただし、これは「他の指標を見なくてよい」という意味ではない。意思決定の軸が曖昧になると、都合のよいメトリクスだけを見て勝ち負けを後付けできてしまう。そのため、あらかじめ主指標を決めるべきである。一方で、プロダクトを壊さないために、ガードレールは必ず併用する必要がある。
OEC の具体例:Hulu の暗黙的フィードバックで考える
Hulu のデータカタログでは、unique_viewed_series は
profile_id ごとに、コンテンツ長の 25%
以上視聴したシリーズを保存するテーブルである。これはレーティングではなく、視聴行動に基づく暗黙的フィードバックである。
暗黙的フィードバックは、ユーザーが明示的に「好き」と言ったわけではない点に注意が必要である。25% 以上視聴したという事実は、少なくとも一定の関心があったことを示す。しかし、それが満足を意味するとは限らない。例えば、家族が同じプロフィールで観たかもしれないし、ながら見だったかもしれないし、途中まで観たが期待外れだったかもしれない。それでも、クリックよりは強く、完走よりは広く取れるシグナルとして実務上有用である。
OEC 候補をいくつか考えると、次のようになる。
1 プロフィールあたりの 25% 以上視聴ユニークシリーズ数。
推薦露出された作品のうち、25% 以上視聴に至った割合。
実験期間中のアクティブ視聴日数。
推薦経由の初回視聴シリーズ数。
長期継続の短期 proxy としての、翌週再訪率や複数日視聴率。
例えば、推薦棚に表示された作品からの 25% 以上視聴率を OEC にするなら、ユーザー について次のように定義できる。
ここで、 は profile に実験期間中に推薦露出されたシリーズ集合である。この指標は「推薦が露出された中で、どれだけ 25% 以上視聴に結びついたか」を測る。ただし、露出数 がユーザーによって大きく違う場合、非常に少ない露出しかないユーザーの比率が不安定になる。そのため、実務ではプロフィール単位の平均、露出単位の平均、最小露出数の条件、重み付けなどを慎重に設計する必要がある。
手を動かす例として、次の 3 プロフィールを考える。
| profile | 推薦露出シリーズ数 | 25% 以上視聴シリーズ数 | 比率 |
|---|---|---|---|
| A | 10 | 2 | 0.20 |
| B | 8 | 1 | 0.125 |
| C | 2 | 1 | 0.50 |
プロフィール単位で平均すると、次の値になる。
一方、露出単位でまとめると、推薦露出合計は 、25% 以上視聴合計は なので、次の値になる。
同じログから計算しても、プロフィール単位平均では 、露出単位平均では になり、値が変わる。これはどちらが常に正しいという話ではない。ユーザーをランダム化単位にしているなら、ユーザー単位の意思決定に合わせてプロフィール単位で集計する方が自然な場合が多い。一方で、推薦枠ごとの効率を見たいなら露出単位の指標も有用である。重要なのは、実験開始前にどちらを主指標として採用するかを決めておくことだ。
パラメータとは何か
パラメータとは、実験で操作する制御可能な変数である。単純な A/B テストでは、1 つのパラメータに 2 つの値を設定することが多い。
Bing の例では、パラメータは「広告タイトルの表示方法」であり、値は「従来の短いタイトル」と「1 行目テキストと組み合わせた長いタイトル」である。
Hulu の推薦であれば、パラメータには次のようなものがある。
推薦候補生成ロジック: 協調フィルタリング中心か、作品 embedding の類似度を混ぜるか。
ランキングモデル: 既存モデルか、新しい特徴量を追加したモデルか。
多様性制御: 同一ジャンルの連続表示を許すか、一定以上分散させるか。
公開終了作品の扱い: 通常順位か、公開終了が近い作品を少し上げるか。
推薦棚の見出し: 汎用的な文言か、ユーザーの視聴履歴に合わせた文言か。
例えば、avg_fingerprint
を使った内容類似推薦を試すなら、パラメータは「候補生成に動画内容
embedding を使うかどうか」である。値は「使わない」と「使う」の 2
つになる。A/B/n テストなら、「使わない」「10% 混ぜる」「30%
混ぜる」のように 3 つ以上の値を持たせることもできる。
実験群とは何か
実験群、つまり Variant は、ユーザーが実際に受け取る体験のことである。パラメータの値が 1 つだけなら、パラメータ値と Variant はほぼ同じに見える。しかし、実務では Variant は単なる設定値ではなく、ユーザーから見える総合的な体験である。
例えば、Hulu の推薦実験で次の 2 群を考える。
Control: 現行の推薦ランキングを使う。
Treatment: 現行ランキングに
avg_mood_tagとavg_fingerprintによる内容類似スコアを追加する。
この場合、Treatment のユーザーは、単に「スコアが変わった」だけではない。実際には、トップページの推薦棚に出る作品、作品の並び、ユーザーが最初に目にするジャンル、視聴済み作品との近さ、新着作品の出やすさなどが変わる。これら全体が Variant である。
教科書では、Control も Variant の一種と考える。これは実務上重要である。なぜなら、実験でバグが見つかった場合、Treatment を止めて全員を Control Variant に戻す、という運用をするからである。Control は「何もしていない状態」ではなく、「比較基準として明示的に管理されているユーザー体験」なのである。
ランダム化単位とは何か
ランダム化単位は、実験群への割当を行う単位である。オンライン実験では、多くの場合ユーザー単位でランダム化する。Hulu
の推薦では、パーソナライズがプロフィール単位で行われるなら、profile_id
をランダム化単位にするのが自然である。
例えば、次のように experiment_id と
profile_id を使ってハッシュ値を作り、50% ずつ Control と
Treatment に割り当てることができる。
この方法の狙いは 2 つある。第一に、同じ profile は何度訪問しても同じ Variant に入る。これを永続的割当という。第二に、ハッシュが十分に一様なら、Control と Treatment に割り当てられるプロフィールの属性分布は平均的に似る。
永続性は、推薦実験では特に重要である。もし同じプロフィールがアプリを開くたびに Control と Treatment を行き来すると、ユーザーは一貫しない推薦体験を受ける。さらに、視聴履歴が Treatment の推薦によって変わった後、次のセッションでは Control の推薦に使われる、といった混入も起きる。これでは、どちらの体験が視聴行動を変えたのか分かりにくくなる。
一方で、ランダム化単位の選択には注意が必要である。
profile_id単位: パーソナライズ推薦と相性がよい。ただし、同じアカウント内の複数プロフィールに影響が及ぶ場合は干渉があり得る。account 単位: 家族内のプロフィール間干渉を避けやすい。ただし、プロフィール単位の推薦モデル評価としては粒度が粗くなる。
session 単位: 短期 UI 実験では使える場合がある。しかし、推薦の学習や視聴履歴への影響が残る場合は不安定になりやすい。
device 単位: デバイス固有の UI 実験では候補になる。ただし、同じプロフィールがテレビ、スマートフォン、Web を使う場合、体験が混ざる。
item または series 単位: 作品側の表示実験には使える場合がある。しかし、ユーザー単位の推薦体験全体を評価したい場合には適さないことが多い。
この節で教科書が「ユーザーをランダム化単位として使うことを強く推奨する」と述べるのは、オンラインサービスではユーザー体験が継続的であり、過去の体験が次の行動に影響するからである。
適切なランダム化が重要である理由
ランダム化の目的は、Control と Treatment の違いを、介入以外の要因で説明しにくくすることである。もし割当が偏っていると、実験結果は信用できなくなる。
例えば、Hulu で profile_id の末尾が偶数なら
Control、奇数なら
Treatment、という割当をしたとする。一見ランダムに見えるかもしれない。しかし、ID
の生成規則に何らかの偏りがある場合、登録時期、国、デバイス、プロフィール種別などと相関する可能性がある。すると、Treatment
の方に新規ユーザーが多い、キッズプロフィールが多い、特定デバイスが多い、といった偏りが生じるかもしれない。
また、「アクティブユーザーだけを後から抽出して比較する」ことにも注意が必要である。Treatment がユーザーのアクティブ化に影響するなら、アクティブになったユーザーだけを見て比較することは、介入後の条件で母集団を選別していることになる。これは post-treatment selection であり、因果解釈を歪める可能性がある。
適切なランダム化では、少なくとも次を確認するべきである。
割当比率が設計通りである。例えば 50:50 の実験なら、Control と Treatment の人数が大きくずれていない。
実験開始前の主要属性や過去行動が両群で大きく偏っていない。
ログ欠損やイベント重複が片方の群に偏っていない。
同じ profile が複数 Variant に入っていない。
実験対象外のユーザーが誤って混ざっていない。
特に、割当比率が期待から大きくずれる現象は SRM、つまり Sample Ratio Mismatch と呼ばれる。SRM が起きている場合、実験結果の解釈はかなり危険である。例えば Treatment のページだけクラッシュしてログが送られない場合、見かけ上 Treatment のユーザー数が少なくなる。これは単なる集計上の問題ではなく、ユーザー体験そのものが壊れている可能性を示している。
A/B/n テストと多変量テストの違い
教科書では、A/B テストという言葉を、実験群が 2 つの場合だけでなく、広くコントロール実験全般を指す言葉として使っている。したがって、A/B/n テストも広い意味では A/B テストである。
A/B/n テストは、1 つのパラメータに複数の値を持たせる実験である。例えば、Hulu の推薦で「内容類似候補をどれくらい混ぜるか」を試すなら、次のような Variant を作れる。
Control: 内容類似候補を混ぜない。
Treatment B: 内容類似候補を 10% 混ぜる。
Treatment C: 内容類似候補を 30% 混ぜる。
Treatment D: 内容類似候補を 50% 混ぜる。
一方、多変量テスト、つまり MVT は、複数のパラメータを同時に動かす。例えば、推薦候補生成ロジックと推薦棚タイトル文言を同時に変える場合である。
| パラメータ | 値 1 | 値 2 |
|---|---|---|
| 候補生成 | 現行モデル | embedding 類似を追加 |
| 棚タイトル | あなたにおすすめ | 視聴履歴に近い作品 |
この 2 つを組み合わせると、合計 4 通りの Variant ができる。MVT は、パラメータ同士の相互作用を見たいときに有用である。例えば、embedding 類似を追加するだけでは効果がないが、「視聴履歴に近い作品」という棚タイトルと組み合わせると効果が出る、ということがあり得る。なぜなら、ユーザーが推薦の意図を理解しやすくなり、作品を選びやすくなるからである。
ただし、MVT は必要サンプルサイズが増えやすく、分析も複雑になる。そのため、最初は単純な A/B テストで主要な仮説を検証し、必要に応じて A/B/n や MVT に進むのが実務的である。
オフライン評価と A/B テストの関係
推薦 ML では、A/B テストだけを見ればよいわけではない。オフライン評価も重要である。なぜなら、オンライン実験はコストが高く、ユーザーに実際の影響を与えるからである。明らかに悪そうなモデルをいきなりオンラインへ出すべきではない。
しかし、オフライン評価だけでは不十分である。暗黙的フィードバックの推薦では、過去ログにいくつかの偏りが含まれる。
露出されなかった作品は、ユーザーが好きだったかどうか分からない。
上位に表示された作品ほど視聴されやすいという position bias がある。
人気作品は多くのユーザーに露出されるため、学習でも評価でも有利になりやすい。
過去の推薦モデルが作ったログで、新しい推薦モデルを評価している。
25% 以上視聴は満足の proxy ではあるが、明示評価ではない。
したがって、オフライン評価は「オンラインで試す価値がある候補を選ぶためのフィルタ」と考えるのがよい。そして、A/B テストは「実際のユーザー体験として価値があるかを確かめる最終的な測定」と考えるべきである。
例えば、オフラインで NDCG@20 が 3% 改善したモデルがあるとする。このモデルは有望である。しかし、オンラインでは推薦棚の上位に似た作品が並びすぎて、ユーザーが新しい作品を発見しにくくなるかもしれない。逆に、オフライン NDCG はあまり伸びないが、多様性や新規性を少し高めたモデルが、オンラインでは視聴日数や継続 proxy を改善するかもしれない。
この意味で、A/B テストは ML モデルの順位付け能力だけでなく、プロダクト体験全体の効果を測っているのである。
この節の用語を Hulu 推薦に対応させる
最後に、教科書の用語を Hulu 推薦の文脈へ対応させると、次のように整理できる。
| 教科書の用語 | 意味 | Hulu 推薦での例 |
|---|---|---|
| OEC | 実験の目的を表す定量指標 | 1 プロフィールあたりの 25% 以上視聴シリーズ数、推薦経由視聴率、視聴日数 |
| Parameter | 実験で操作する制御可能な変数 | 候補生成ロジック、ランキングモデル、推薦棚タイトル、多様性制御 |
| Level | Parameter が取り得る値 | 現行モデル、新モデル、embedding 混合率 10%、embedding 混合率 30% |
| Variant | ユーザーが受ける体験 | Control の推薦面、Treatment の推薦面 |
| Control | 比較基準となる既存体験 | 現行推薦アルゴリズムと現行 UI |
| Treatment | 試したい新しい体験 | 新しい推薦モデル、新しい棚構成、新しいランキング |
| Randomization Unit | 実験割当の単位 | profile_id、account、session、device |
| Metric | ログから計算される評価値 | 再生開始率、25% 以上視聴率、完走率、離脱率、クラッシュ率 |
この表で特に重要なのは、OEC と Metric の違いである。Metric はたくさんあってよい。むしろ、実験を理解するには多くの補助指標が必要である。しかし、OEC は意思決定の中心であり、「この実験は何を良くするためのものか」を表す。OEC が曖昧だと、実験後に都合のよい指標を選んで「勝った」と言えてしまう。これは実験文化を壊す。
まとめ
この節は、A/B テストの入門的な用語説明に見えるが、実務上のメッセージはかなり深い。Bing の事例は、小さな変更が巨大な価値を生む可能性を示している。同時に、そのような価値は事前には見積もりにくく、専門家の意見だけでは発見できないことも示している。
Hulu の動画推薦に引き寄せると、A/B
テストは「新しい推薦モデルが本当にユーザー体験を改善するか」を測るための因果推論の仕組みである。unique_viewed_series
のような 25% 以上視聴ログは、暗黙的フィードバックとして OEC
や補助指標に使える。しかし、それだけで満足度や長期価値を完全に表せるわけではない。そのため、主
OEC を明確にし、同時にガードレールを設定する必要がある。
また、推薦実験ではランダム化単位が特に重要である。パーソナライズが
profile 単位なら、基本的には profile_id
を用いた永続的なランダム化が自然である。ただし、家族アカウント内の干渉、複数デバイス利用、セッションをまたぐ学習効果なども考慮しなければならない。
結局のところ、A/B テストとは「出してみて数字を見る」だけの作業ではない。正しいランダム化、明確な OEC、信頼できるログ、異常検知、ガードレール、そして結果を解釈するドメイン知識がそろって初めて、プロダクト改善のための信用できる実験になるのである。