ch2-3 実験の実施とデータ収集:信用できる結果を意思決定につなげる
この節は、実験仮説と必要標本数を決めた後に、「実験を正しく動かし、結果を信用してよいかを確認し、ローンチするかを決める」段階を扱う。A/B テストは統計検定だけでは成立しない。ランダムに割り当てたつもりでも、実際には一部の profile にしか介入が届いていない、群ごとにログの欠損率が違う、集計で variant を取り違えた、といった問題があれば、p 値や信頼区間は正しく計算されていても結論は信用できない。
Hulu の動画推薦では、この点が特に重要である。推薦モデルは、単に作品を表示するだけでなく、候補生成、ランキング、棚配置、キャッシュ、クライアント実装、再生、視聴ログまでの複数コンポーネントをまたぐ。さらに、主な反応は「好き」などの明示的評価ではなく、作品詳細の表示、再生開始、視聴秒数、25% 以上視聴、継続視聴といった暗黙的フィードバックである。したがって、どの profile がどのモデルに割り当てられ、実際にどの推薦を見て、どの作品をどの程度視聴したかを、後から一貫して復元できなければならない。
この節の結論を先に言えば、実験結果は次の順序で扱うべきである。
割当、実際の露出、イベント計測を記録する。
集計前に、実験が設定どおり実行されたことを不変性メトリクスで検証する。
主要メトリクスの差、信頼区間、p 値、ガードレールを一緒に読む。
統計的有意性だけでなく、効果の大きさ、実装・運用コスト、判断を誤る損失を考えてローンチ判断をする。
実験を実行するために必要な二つの仕組み
教科書が挙げる二つの仕組みは、役割が異なるが、どちらか一方が欠けても実験は成立しない。
実験プラットフォームは、「誰に、いつ、どの variant を見せるか」を決め、同じ profile に一貫して同じ variant を返す仕組みである。
計測基盤は、「その profile が何を見て、何を選び、どのように視聴したか」を記録し、variant と結合できるようにする仕組みである。
前者だけでは、モデル A と B に何人割り当てたかは分かっても、視聴行動が分からない。後者だけでは、再生数は分かっても、それがモデル A と B のどちらによる結果かを因果的に比較できない。
実験プラットフォームが担うこと
推薦ランキングの実験であれば、プラットフォームは概ね次を行う。
実験 ID、対象条件、開始・終了時刻、variant と配分比を管理する。
対象となる
profile_idが eligible かを、割当前に判定する。profile_idと実験 ID から決定論的に bucket を計算し、Control / Treatment を割り当てる。同じ profile が別日・別セッション・別デバイスで訪れても、原則として同じ variant を返す。
割当、設定バージョン、実際に返した variant をログに残す。
決定論的な割当とは、例えば
hash(experiment_id, profile_id) の値で bucket
を決める考え方である。これにより、実験中にアプリを閉じても、翌日に別の
variant へ変わることを防ぐ。ユーザー単位の介入で variant
が頻繁に切り替わると、処置が混ざり、どの体験が行動を変えたか分からなくなる。
ただし、hash による配分だけで「ランダム化は正しい」とは言えない。対象外条件、ログイン前後の ID 結合、キャッシュ、SDK のバージョン差、fallback によって、実際に variant が届いた profile の構成が変わる可能性がある。そのため、後述する割当ログと露出ログの双方が必要になる。
計測基盤が担うこと
推薦実験では、少なくとも「割当」「露出」「行動」「成果」を区別して記録する。
| 段階 | 記録すべき主な項目 | Hulu での例 | このログがない場合に起きること |
|---|---|---|---|
| 割当 | experiment_id、variant、profile_id、割当時刻、設定バージョン |
profile A は ranker_v2、profile B は現行 ranker |
誰を比較すべきか分からない。 |
| 露出 | 実際に描画した棚、作品、順位、リクエスト ID、露出時刻 | 「あなたへのおすすめ」の 3 番目に『葬送のフリーレン』を表示 | 介入が本当に届いたか、何を見せたかが分からない。 |
| 中間行動 | 詳細遷移、タップ、再生開始、検索、スクロール | select_content、watch_start、棚名、順位 |
効果がファネルのどこで起きたか診断できない。 |
| 成果 | 視聴秒数、25% 到達、ユニーク series、再訪、継続 | content_viewing.watched_seconds、unique_viewed_series |
クリックだけの局所最適化になる。 |
hj-data-01.intermediate.ga4_unnested_cleaned_log には
screen_view、select_content、watch_start、masthead_imp
などの event_name
と、event_params_tray_area_name、event_params_tray_order、event_params_series_id、user_id
がある。これらはクライアント側の露出・選択を確認するための候補になる。一方、hj-data-01.report.content_viewing
には
profile_id、series_id、asset_id、watched_seconds、視聴開始・終了時刻があり、実際の視聴量を集計できる。また、hj-data-01.report.unique_viewed_series
は、動画コンテンツ長の 25% 以上を視聴したシリーズを profile
単位で持つ。
ただし、これらの既存ログに実験 ID と variant
が自動で入っているとは限らない。実験プラットフォームの割当ログと、共通の
profile_id、時刻、必要なら request ID
で安全に結合できるかを、実験開始前に検証する必要がある。特に
user_id は仕様上 profile_id
が格納されるが、ログイン前、複数 profile、ID
未送信、遅延到着の扱いは実装仕様として明文化すべきである。
割当ログと露出ログを分ける理由
「variant を返した」という割当と、「ユーザー画面に推薦棚が表示された」という露出は同じではない。ネットワーク失敗、画面遷移、キャッシュ、アプリの古いバージョン、描画前の離脱によって、割り当てられても実際には見ていない profile が存在する。
主要な因果推定では、原則として割当を基準にする Intent-to-Treat 分析を用いる。すなわち、eligible な profile を Control / Treatment に割り当てた時点で分母に含め、割当後に実際に棚を見たか、クリックしたか、再生したかで主要分析の対象を選別しない。
露出ログは不要という意味ではない。露出ログは、次の診断に不可欠である。
Treatment のコードが実際に配信されたか。
variant ごとに棚の描画率、カード数、順位、fallback 率が異常に違わないか。
OEC の差が、露出率、作品クリック率、再生開始率、25% 到達率のどこで生じたか。
想定と異なるプラットフォーム、キッズ profile、対象外地域に介入が漏れていないか。
ワークド例:露出者だけを主分析にすると比較対象が変わる
各群 1,000 profile にホーム推薦棚の実験を割り当て、OEC を「7 日間の 25% 以上視聴ユニークシリーズ数」とする。説明を簡単にするため、棚を見なかった profile の OEC は 0 と仮定する。
| 群 | 割当 profile 数 | 棚を実際に見た profile 数 | 露出者の平均 OEC | 全割当 profile の平均 OEC |
|---|---|---|---|---|
| Control | 1,000 | 500 | 4.0 | |
| Treatment | 1,000 | 700 | 3.0 |
露出者だけなら Treatment は 3.0 本、Control は 4.0 本なので、Treatment が悪いように見える。しかし Treatment が「推薦棚を見てもらえる profile」を 500 人から 700 人へ増やした結果なら、割当 profile 全体の効果は次である。
棚閲覧は介入後に起きる変数であり、Treatment がその人数を変え得る。露出者だけを比べると、二群で異なる人々を比較することになる。したがって、主要な効果推定は割当された eligible profile 全体で行い、露出者分析は原因を診断する補助分析として扱う。
推薦実験のデータを、後から再現できる形で作る
実験終了時に慌てて複数テーブルを結合すると、再現性と監査可能性が下がる。実務では、実験 ID と分析期間を入力すると、profile 単位で一行に集約された分析データセットを作れる状態が望ましい。
profile 単位の分析データセットのイメージ
ユーザーランダム化で主要 OEC を 7 日間の値として測るなら、概念的には次の列を持つデータセットになる。
| 列 | 意味 | 例 |
|---|---|---|
experiment_id |
実験を特定する ID | home_ranker_2026_07 |
variant |
割り当てた群 | control / treatment_v2 |
profile_id |
ランダム化単位 | ハッシュ化済み profile ID |
assigned_at |
割当時刻 | 2026-07-06 00:00 JST |
eligible_at_assignment |
割当前に対象条件を満たしたか | true |
exposed |
実際に対象棚が描画されたか | true / false |
impression_count |
対象棚の露出回数 | 8 |
recommendation_click_count |
対象棚からの詳細遷移等 | 2 |
watch_start_count |
再生開始数 | 1 |
watched_seconds_7d |
割当後 7 日の総視聴秒数 | 5,400 |
unique_series_25pct_7d |
割当後 7 日の 25% 視聴ユニーク series 数 | 2 |
pre_experiment_viewing |
割当前の視聴量 | 7,200 |
platform_at_assignment |
割当前のプラットフォーム | TV |
pre_experiment_viewing や
platform_at_assignment
は、実験前に観測された共変量である。これらは群のバランス確認、事前定義したセグメント分析、分散削減に使える。一方、exposed、クリック数、実験期間中の視聴量は介入後の変数である。これらを主要
OEC の分母を絞る条件に使うと、因果推定を歪める可能性がある。
時刻と集計窓を固定する
視聴ログには、イベント発生時刻、取り込み時刻、日付パーティションが混在する。GA4
の event_timestamp は UTC
のマイクロ秒であり、event_date
はユーザー端末のタイムゾーン基準である。content_viewing の
start_date は DATETIME、date
は視聴日、unique_viewed_series.last_viewing_date は JST
日付である。これらを混在させると、実験開始直後や終了直後のイベントが
variant 間で不公平に落ちる可能性がある。
したがって、次を事前に固定する。
割当時刻と分析時刻に用いるタイムゾーン。
割当日を含めるか、割当から厳密に 7 日後までを測るか。
遅延到着イベントを待つためのデータ確定日。
実験終了後に継続して測る長期指標の観測窓。
例えば、JST で 2026 年 7 月 6 日 00:00 に開始する実験で、profile ごとに割当から 7 日間を測るなら、7 月 12 日 23:59:59 JST までを集計する。日付境界だけで単純に切る場合でも、Control / Treatment の両方に同じルールを適用し、分析仕様に残す必要がある。
結果を見る前に行う正当性チェック
主要 OEC の p 値を見る前に、実験が信用できる前提を確認する。この段階で見るのが、不変性メトリクスとガードレールメトリクスである。
不変性メトリクスとは、今回の介入では原理的に変わらないはず、あるいは変わったら実験・計測上の異常を疑うべきメトリクスである。ただし、「同じ値でなければならない」とは、標本平均が一桁まで完全一致するという意味ではない。ランダム割当である以上、有限標本では小さな差が必ず生じる。期待差がゼロという仮説の下で、その差が不自然に大きくないかを確認する。
1. 実験の信用度に関する不変性メトリクス
これは、実験設計・配信・ログ結合が正しいかを確かめるメトリクスである。
| 確認項目 | 本来の期待 | 異常だった場合の主な疑い |
|---|---|---|
| 群ごとの割当人数 | 事前の配分比に近い | hash、対象判定、実験 ID、ログ欠損、実装分岐の問題。 |
| 割当前の視聴量・会員属性 | 群間で系統的差がない | ランダム化単位の不整合、ID 結合不良、対象条件の群依存。 |
| variant の配信率 | 設計どおりに近い | SDK、キャッシュ、fallback、アプリバージョン差。 |
| ログ送信率 | 群間で大差がない | Treatment 側でイベント実装を壊した、クライアントクラッシュ。 |
| キャッシュヒット率 | 介入がキャッシュを変えないなら同程度 | key の設計、variant 混在、キャッシュ経路の差。 |
| 実験前のイベント | 介入後に変化しない | 時間結合・variant 付与・分析窓のバグ。 |
群人数の確認は Sample Ratio Mismatch、略して SRM の検出として特に重要である。例えば Control / Treatment を 50% / 50% に設定したのに、解析対象が大きく 50% / 50% から外れているなら、その後の OEC 差を読む前に原因を調べるべきである。単純な偶然で片付けるのではなく、期待配分からのずれをカイ二乗検定などで評価する。
ワークド例:SRM を計算する
50% / 50% に割り当てる設計で、合計 100,000 profile の割当ログを集計したところ、Control が 53,000、Treatment が 47,000 だったとする。各群の期待人数は 50,000 である。二群の Pearson のカイ二乗統計量は次の通りである。
自由度 1 のカイ二乗分布で 360 は極端に大きく、偶然の割当誤差とは考えにくい。この段階では「Control のほうが多いが、OEC は Treatment が勝ったので問題ない」とは判断しない。例えば、ログイン済み profile だけで variant を付け、ログイン前 profile を variant 不明として落とした、ある app version だけで Treatment が無効化された、といった原因を調べる。SRM は OEC の差を直接説明しない場合もあるが、ランダム化またはデータ処理の前提が壊れている危険信号である。
2. 組織的なガードレールメトリクス
組織的なガードレールは、多くの実験で悪化を許容しないプロダクト健全性の指標である。今回の仮説が推薦精度であり、ランキング API の速度を変える設計ではないなら、例えばレイテンシやエラー率が大きく変わることは意外である。変わったなら、実装副作用または意図せぬ経路変更を疑う。
Hulu の推薦で考えられる例は次の通りである。
| 指標 | なぜ見るか | 解釈上の注意 |
|---|---|---|
| 推薦 API の p95 / p99 レイテンシ | 新モデルの特徴量取得や推論が画面表示を遅くしていないか。 | 推論方式を変える実験なら、完全な不変性ではなく重要なガードレールである。 |
| エラー率・fallback 率 | 新モデルが失敗して現行モデルや空棚へ fallback していないか。 | Treatment だけ高いなら、効果推定は「新モデルそのもの」ではなく失敗込みの効果になる。 |
| クラッシュ率 | クライアント計測・描画が安定しているか。 | クラッシュでログが失われれば、観測される profile 集団も変わる。 |
| 再生開始失敗率・バッファリング | 視聴体験を損ねていないか。 | ランキングの変更でも、推薦するコンテンツ種別が変われば間接的に動き得る。 |
| キッズ安全性・年齢制約違反 | 許容できない露出がないか。 | 統計的に有意でなくても、重大な一件で停止すべき場合がある。 |
| CPU・メモリ・推論コスト | 全面展開時の運用費用を見積もる。 | 有意な視聴改善とトレードオフになり得る。 |
この種の指標は、常に「差が出たらバグ」とは限らない。新しいランキングモデルが重い特徴量を使えば、レイテンシ悪化は介入の因果的結果である。それでも、推薦の OEC が改善したからといって無視してよいわけではない。後述するローンチ判断で、便益と運用コストのトレードオフとして扱う。
ワークド例:不変性の失敗と、ガードレールの悪化を分ける
新ランキングの実験で、次の二つの結果が出たとする。
| 指標 | Control | Treatment | まず取るべき行動 |
|---|---|---|---|
| 割当前 28 日の平均視聴秒数 | 31,200 秒 | 38,900 秒 | 実験結果を保留し、割当・ID 結合・対象条件を調査する。介入前の差はモデル効果ではない。 |
| 推薦 API p95 レイテンシ | 180 ms | 260 ms | 実装とコストを確認し、主要 OEC の便益と合わせて判断する。 |
一つ目は、実験開始前の値である。Treatment に割り当てられる前から平均視聴秒数が大きく違うなら、ランダム化やデータ結合に問題がある可能性が高い。これは信用度を壊す不変性チェックの失敗である。
二つ目は、実験後のシステム指標である。新モデルがより遅い推論を行うなら、差は実際の処置によって生じたかもしれない。これはデータのバグと決めつけず、ローンチ時に許容できるかを評価するガードレールの悪化である。この二つを混同しないことが重要である。
結果表をどう読むか
教科書のクーポン入力欄の実験は、Control、常時表示する介入群 1、クリックして開く介入群 2 を比べる。表は、1 ユーザー当たり収益を主要メトリクスとして、各介入を共通の Control と比較した結果である。
| 比較 | 介入群の収益 | Control 群の収益 | 差 | p 値 |
|---|---|---|---|---|
| 介入群 1 vs Control | 3.21 | () | 0.0003 | |
| 介入群 2 vs Control | 3.21 | () |
上の第 2 行の信頼区間は、本文にある ではなく、差と p 値に整合するよう と表記した。正の を含む区間ならゼロを含み、p 値が になることとは整合しないため、提示文の符号は転記上の誤りと考えるのが自然である。
介入群 1 の数値を手で確認する
Control の 1 ユーザー当たり収益が 、介入群 1 が なら、絶対差は次になる。
相対差は次の通りである。
95% 信頼区間 はゼロを含まない。そのため、「真の収益差がゼロ」という帰無仮説に対して両側 5% 検定を行えば棄却する。しかも区間全体が負であるため、単に「何らかの差がある」ではなく、収益の悪化方向の差が支持されている。
ただし、ここでも確認すべきは収益だけではない。購入者一人当たりの購入額が下がったのか、購入を完了するユーザーの割合が下がったのかで、プロダクト上の原因と対応が変わる。教科書では後者、すなわちクーポン欄によって購入完了者が減ったことが収益減少の経路と解釈している。
Hulu の推薦実験に置き換えた結果表
例えば、新ランキングの実験で主要 OEC を「7 日間に 25% 以上視聴したユニークシリーズ数 / eligible profile」とし、次の結果が出たとする。
| 比較 | Treatment | Control | 絶対差 | 相対差 | 95% 信頼区間 | p 値 |
|---|---|---|---|---|---|---|
| 新ランキング vs 現行 | 2.040 本 | 2.000 本 | 本 | 0.009 |
絶対差と相対差は次のように確認できる。
この結果は、統計的には改善を示す。しかし、即座に「新モデルを全面展開する」とは決めない。例えば、主要 OEC の改善が、人気作品だけへの集中、総視聴秒数の低下、推薦 API コストの増加、キッズ profile への不適切露出と引き換えでないかを確認する。また、事前に定めた実用下限が +3% なら、この結果は統計的に有意でも事業上十分ではない可能性がある。
「塗りかけの扉」の実験が節約するもの
クーポン実験では、完全なクーポン発行・検証・割引・利用履歴・不正対策を実装する前に、購入確認ページにクーポン入力欄だけを置いた。ユーザーが入力すると無効と扱われる設計は、クーポン機能そのものの価値を測るのではない。クーポン欄の存在が、購入完了前のユーザーの心理と行動を悪化させないかを、低コストで調べる「塗りかけの扉」の実験である。
この結果、二つの UI で一貫した収益悪化が見え、完全なクーポンシステムの開発費だけでなく、導入後に継続して失う収益まで考える根拠が得られた。テストは「機能が成功することを証明する」ためだけではない。高価な実装に進む前に、採用しないという意思決定を早く行うためにも価値がある。
Hulu の推薦でも同じ発想を使える。例えば、会話型の作品探索機能を本格実装する前に、既存の推薦候補に「今夜は何が見たいですか?」という入口を付け、数個の選択肢で既存の検索・推薦結果へ導くことはできる。この実験で測るのは、大規模言語モデルによる対話品質ではなく、対話的な入口が作品探索、再生開始、25% 視聴、検索離脱に与える影響である。
ただし、塗りかけの扉は、何を測っていないかを明示する必要がある。例えば、実際には作れない対話体験を約束する、ユーザーを意図的に誤認させる、信頼を損なう場合は、短期メトリクスが良くても採用できない。Hulu の視聴体験・ブランド・コンテンツ権利・年齢配慮に照らした倫理レビューと、失敗時の安全な fallback を先に設計すべきである。
結果から意思決定へ:統計と文脈を分けて考える
統計検定は「観測差がゼロと整合するか」と「推定の不確実性」を示す。一方、ローンチ判断は、効果の大きさ、実装費、運用費、リスク、変更の寿命、学習価値を含む意思決定である。したがって、統計的な結論と意思決定は同じではない。
ローンチの損益を粗く分解する
全面展開の価値は、単純化すれば次のように考えられる。
ここで Expected benefit は、平均効果だけでなく、対象 profile 数、変更が有効である期間、長期継続への寄与を含む。Ongoing operation cost には、推論 GPU / CPU、特徴量パイプライン、モデル監視、障害対応、モデル更新、説明可能性やコンテンツ制約の保守が含まれる。Risk cost には、性能悪化、レイテンシ、ブランド毀損、キッズ安全性、機会損失が含まれる。
ワークド例:同じ +1% でもローンチ判断が違う
二つの施策が、どちらも実験で 7 日視聴秒数を +1% 改善したとする。
| 施策 | 全面展開に必要な追加コスト | 想定寿命 | 判断の方向 |
|---|---|---|---|
| A: 既存候補の棚タイトルを改善 | 低い。クライアント文言の変更と確認のみ。 | 数週間のキャンペーン | 小さなプラスでも展開しやすい。 |
| B: 新しいリアルタイム ranker | 高い。低レイテンシ特徴量、推論基盤、監視、オンコールが必要。 | 長期 | +1% がその継続コストとリスクを上回るかを精査する。 |
施策 A は、実装・保守費がほぼゼロで、誤って展開してもすぐ戻せるなら、実用的有意性の下限を低くできる。施策 B は、同じ平均改善でも p95 レイテンシや推論費用を含めて正味価値がプラスである必要がある。統計的な差の大きさが同じでも、最適な意思決定は同じにならない。
判断を誤ったときの損失も非対称である
ローンチ判断には、少なくとも次の二種類の誤りがある。
| 判断 | 実際には良い変更 | 実際には悪い変更 |
|---|---|---|
| ローンチする | 正しい採用 | 悪化を全面展開する。視聴・ブランド・コストを失う。 |
| ローンチしない | 有望な改善を見送る。機会損失。 | 正しい見送り |
短期間だけ表示するキャンペーン見出しなら、誤って採用しても影響期間は短い。逆に、推薦の基盤モデルを置き換える判断は、多数の profile と長期間に影響し、ロールバックにも時間がかかる。このため、後者はより狭い信頼区間、強いガードレール、段階展開、長期指標の確認を要求するのが合理的である。
図 2.4:統計的有意性と実用的有意性を同時に読む
図 2.4 の中央の実線は差がゼロである位置、左右の破線は「実用上意味がある」と見なす負・正の境界である。黒い四角は推定効果、横線はその信頼区間を示す。ここでは正方向を望ましい改善と考える。
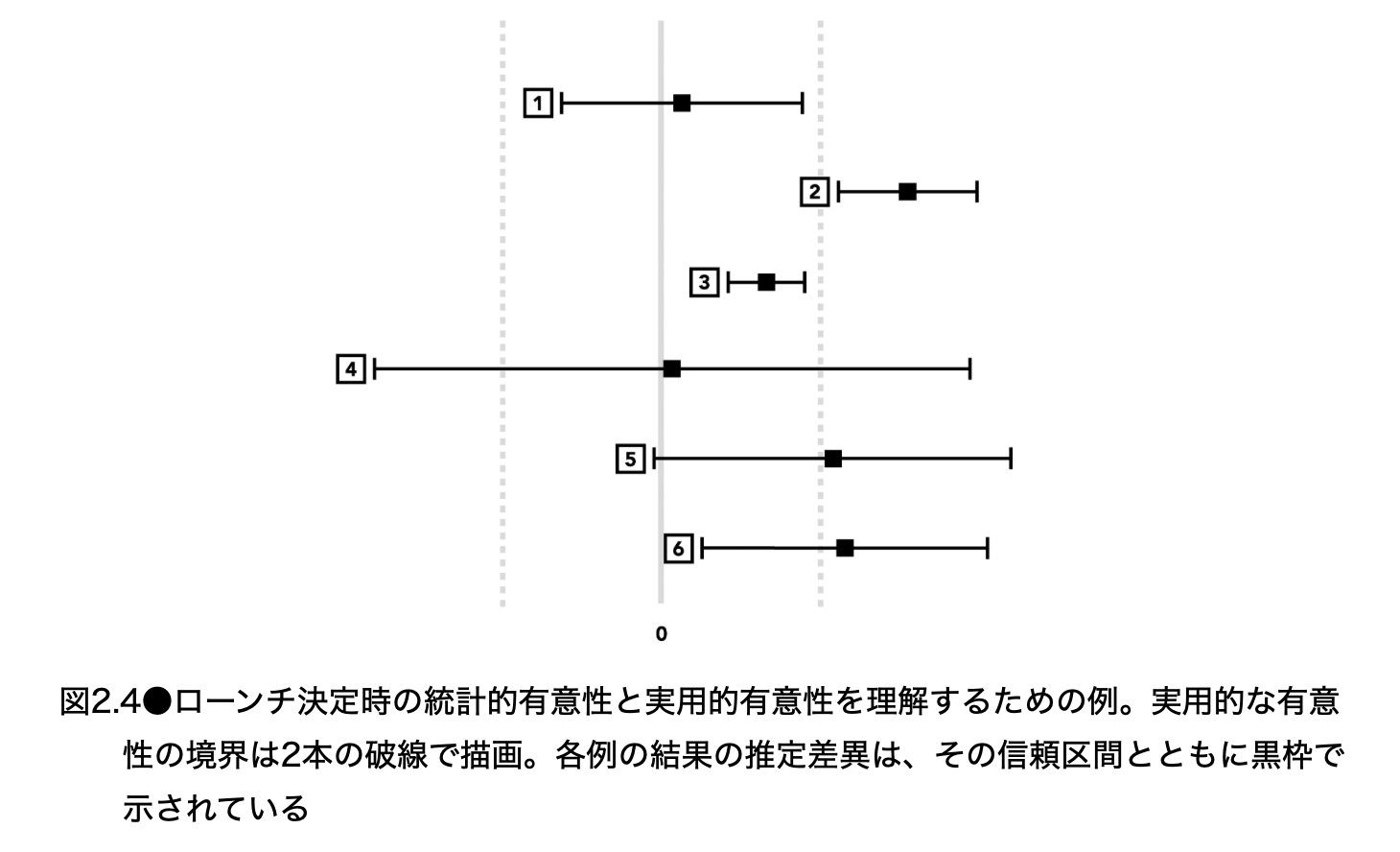
この図の読み方では、二つの問いを順に分けると混乱しにくい。
信頼区間はゼロを含むか。含まなければ、両側 5% 検定では統計的に有意である。
信頼区間と推定効果は、実用的な境界に対してどこにあるか。価値のある大きさをどの程度支持または否定しているかを見る。
例 1:統計的には非有意だが、大きな効果はおおむね除外できる
例 1 の信頼区間はゼロをまたぐため、統計的有意ではない。しかし、信頼区間全体が左右の実用境界の内側に収まっている。したがって、大きな改善も大きな悪化も起きていないことを、少なくとも実用判断に必要な精度で示唆している。
Hulu の例では、実用境界を「7 日の 25% 視聴ユニークシリーズ数で 」とし、推定相対差が 、95% 信頼区間が だった場合を考える。ゼロを含むため勝ちとは言えない。一方で、区間は と の内側にあり、事業上意味があるほどの改善・悪化はおおむね除外できる。実装コストがあるなら見送るのが自然であり、低コストで追加学習価値があるなら再実験する余地がある。
例 2:統計的にも実用的にも改善を支持する
例 2 の信頼区間はゼロより正側にあり、さらに実用的な正の境界より右側にある。したがって、効果が正であるだけでなく、最小限価値があると定めた大きさを上回ることも支持する。これはローンチに最も直接的な根拠を与える形である。
例えば推定相対差が 、95% 信頼区間が 、実用下限が なら、区間全体が実用下限を上回る。ガードレールが健全で、実装・運用コストも許容できるなら、段階的な全面展開を選ぶ根拠が強い。
例 3:統計的には有意でも、実用上は小さい
例 3 の信頼区間はゼロを含まないため、改善方向の統計的有意差である。しかし、実用的な正の境界の内側にある。これは大規模トラフィックで非常に起こりやすい。
例えば、推定相対差が 、95% 信頼区間が 、実用下限が とする。この場合、+0.8% という効果の符号にはかなり自信を持てるが、+3% を必要とする高コストな新 ranker の価値を支持してはいない。小さな UI 変更なら採用する余地がある一方、基盤の置換なら見送る、または別の改善を探す判断になる。
例 4:推定値は中立でも、精度不足で大きな影響を除外できない
例 4 は点推定がほぼゼロだが、信頼区間が左右の実用境界を大きくまたいでいる。これは「効果なし」ではなく、「大きな改善も大きな悪化もあり得るほど、データが足りない」である。
例えば、推定相対差が 、95% 信頼区間が 、実用境界が なら、点推定だけで中立と判断してはならない。新モデルに価値がある可能性も、大きな害がある可能性も残る。標本数を増やす、実験期間を延ばす、分散を下げる設計を使う、または不確実性を受け入れられる小規模ランプアップにとどめる必要がある。
例 5:実用的な改善に見えるが、統計的な確信が足りない
例 5 の点推定は実用境界の外側にある。しかし信頼区間がゼロを含むため、効果がない可能性を棄却できない。都合よく読めば有望だが、偶然の大きな差である可能性も残っている。
例えば、推定相対差が 、95% 信頼区間が 、実用下限が とする。新モデルは有望に見えるが、信頼区間の下端はわずかに悪化である。再実験または追加標本で精度を上げるのが基本である。変更が短命なキャンペーンで、採用・不採用の損失が小さく、すぐ戻せるなら、限定的なローンチを選ぶ余地はある。その場合も、不確実性を「勝ち」と言い換えてはならない。
例 6:統計的には有意で、実用的改善の可能性が高いが下限は届かない
例 6 の信頼区間はゼロより正側にあるため、統計的有意である。また、点推定は実用境界を超えている。しかし、信頼区間の下限は実用境界を下回る。このため、改善は支持されるが、「少なくとも実用下限を超える」とまでは確定していない。
例えば、推定相対差が 、95% 信頼区間が 、実用下限が とする。ローンチするかだけを問うなら、低リスクでロールバック可能な変更なら穏当な採用判断になり得る。ただし、実用下限未満の真の効果も残るため、高コスト・高リスクの全面置換なら、追加実験で精度を上げるのが望ましい。
Hulu の推薦実験におけるローンチ判定の実務フロー
ここまでを実務で使える形にすると、次のようになる。
実験開始前に、主要 OEC、ガードレール、実用下限、対象 profile、割当単位、分析窓、停止規則、主要セグメントを固定する。
実験中は、SRM、variant 配信率、露出率、エラー率、重大な安全性ガードレールを監視する。通常の p 値を毎日見て都合のよい日に終了しない。
実験終了後、イベント遅延を考慮してデータを確定する。割当前の共変量、群人数、ログ欠損を確認し、正当性チェックに失敗していれば OEC の解釈を保留する。
事前定義した Intent-to-Treat 母集団で、群ごとの人数、平均、絶対差、相対差、95% 信頼区間、p 値を算出する。
OEC の因果経路を診断指標で確認する。例えば新 ranker なら、棚露出、作品詳細遷移、再生開始、25% 到達、総視聴秒数のどこが変わったかを見る。
ガードレール、事前定義セグメント、日次推移、コンテンツイベントを確認する。探索的なセグメント結果は、次の仮説を作る材料として扱い、偶然有意な一群だけで全面展開を決めない。
図 2.4 のように、信頼区間と実用境界の位置関係を確認し、実装・保守・運用・失敗時の損失を含めて、全面展開、段階展開、追加実験、見送りを決める。
このフローの目的は、ローンチを遅くすることではない。むしろ、信用できない数字で誤った全面展開をすることと、価値のない開発を続けることを避け、必要なときに速く意思決定することである。
よくある失敗と防止策
| 失敗 | なぜ問題か | 防止策 |
|---|---|---|
| variant を分析テーブルに後付けで推測する | 実際の割当・fallback・ID 不整合を復元できない。 | 割当ログを一次データとして保存する。 |
| クリックした profile だけを比較する | クリックは介入後の変数であり、選択バイアスが入る。 | eligible profile 全体の Intent-to-Treat を主分析にする。 |
| OEC の p 値を先に見る | SRM や計測欠損があると、統計量の前提が壊れる。 | 不変性・ガードレールを先に確認する。 |
| レイテンシ悪化を「推薦とは無関係」と無視する | 実際のユーザー価値と運用コストを見落とす。 | 因果的な副作用としてガードレールに含める。 |
| 統計的有意なら自動でローンチする | 効果が小さく、コストやリスクが上回る場合がある。 | 実用下限と正味価値を事前に定める。 |
| 非有意なら効果なしと結論する | 広い信頼区間なら、大きな改善・悪化を除外できない。 | MDE と信頼区間を確認し、必要なら追加実験する。 |
| 作品配信・祝日・障害を記録しない | 日次変動の原因を誤ってモデル効果と解釈する。 | 実験カレンダーとコンテンツイベントを結果表に併記する。 |
この節の要点
信用できる A/B テストには、variant を一貫して割り当てる実験基盤と、割当・露出・行動・成果を結合できる計測基盤の両方が必要である。
Hulu の推薦では、
profile_idを軸に、実験割当、GA4 の露出・選択イベント、content_viewingの視聴量、unique_viewed_seriesの 25% 視聴を再現可能に結合する設計が重要である。主要 OEC を見る前に、SRM、割当前共変量、ログ欠損、配信率などの不変性メトリクスを確認する。ここで異常があれば、結果の解釈を保留する。
ガードレールは、実験のバグを見つけるためだけではない。レイテンシ、エラー、キッズ安全性、推論コストのような副作用を、ローンチ判断に含めるための指標である。
p 値と信頼区間は統計的結論を与えるが、ローンチ判断には実用下限、実装・運用コスト、判断を誤る損失、ロールバック可能性が加わる。
図 2.4 のように、ゼロだけでなく実用的な境界に対して信頼区間がどこにあるかを見ると、「勝ち」「負け」「精度不足」「低コストなら採用可能」を区別できる。