ch1-3 継続的な改善:小さな実験の積み重ねと戦略のフィードバックループ
この節の中心メッセージは、オンラインプロダクトの成長は、たいていの場合、少数の巨大な勝ちだけではなく、多数の小さな改善の積み重ねによって生まれる、ということである。第 1 章の冒頭では Bing の広告タイトル変更のような大きな成功例が紹介されたが、実務ではそのような大勝ちはまれである。むしろ、0.1% や 0.5% のような小さな改善を継続的に見つけ、信用できる形で積み上げていくことが重要である。
Hulu の動画推薦でも同じである。新しい推薦モデルを 1 回出しただけで、全社の主要メトリクスが一気に 10% 改善することはあまり期待できない。現実には、候補生成、ランキング、既視聴除外、公開終了作品の扱い、棚タイトル、レスポンス速度、デバイス別 UI、ログ品質、キッズプロフィールの安全性など、多数の小さな改善を積み重ねていくことになる。
この節は、その継続的改善の考え方を、Google 広告、Bing 関連性、Bing 広告、Amazon の実験、パフォーマンス改善、マルウェア削減、バックエンドアルゴリズム変更、さらに戦略と戦術の関係という複数の例で説明している。
小さな改善はなぜ小さく見えるのか
教科書は、主要メトリクスの改善は多くの小さな変更によって達成されると述べている。ここで大切なのは、個々の実験の効果が「希釈」されることが多いという点である。
例えば、ある変更がユーザー全体ではなく、ユーザーの一部にしか影響しないとする。影響を受けるユーザーでは 5% の改善があっても、そのユーザーが全体の 10% しかいなければ、全体メトリクスへの影響は単純には 0.5% 程度になる。
式で書くと、全体リフトは次のように近似できる。
ここで、 は変更の影響を受けるユーザー比率、 は影響を受けるユーザー内でのリフトである。
例えば、Hulu で「公開終了が近い SVOD 作品を少し上位に出す」推薦変更を考える。この変更は、全ユーザーに影響するわけではない。実験期間中に、公開終了が近い作品を推薦候補として持つプロフィールだけに効く。
具体的に、全 profile のうち 12% だけがこの変更の影響を受け、その対象 profile では 25% 以上視聴ユニークシリーズ数が 4% 改善したとする。このとき、全体リフトは次のように見積もれる。
つまり、対象ユーザー内では 4% という意味のある改善でも、全体 OEC では 0.48% に見える。これは失敗ではない。むしろ、対象領域が限定されている実験では自然な見え方である。
Hulu 推薦での希釈の具体例
もう少し手を動かして考える。OEC を「14 日間で 1 profile あたり 25% 以上視聴したユニークシリーズ数」とする。Control の全体平均が 本だったとする。
新しい候補生成ロジックは、アニメをよく観る profile のうち、さらに未視聴の関連シリーズが十分にある profile にだけ影響する。この対象 profile が全体の で、対象 profile では平均が 本から 本へ増えたとする。対象内リフトは次の通りである。
一方、対象外 profile の平均は変わらず 本だとする。全体 Control 平均は次のように表せる。
Treatment の全体平均は次のようになる。
全体リフトは次の通りである。
対象内では 5% 改善しているが、全体では約 1.17% 改善に見える。この例から分かるように、全体 OEC だけを見ると、局所的には強い改善を小さく見積もることがある。したがって、実験結果を見るときは、全体 OEC と、事前に定義した対象セグメントの両方を見ることが重要である。ただし、実験後に都合のよいセグメントを探すのではなく、仮説に基づいて事前にセグメントを決めておく必要がある。
小さな改善は累積する
小さな改善は、単独では地味に見える。しかし、継続的に積み上がると大きな差になる。単純化して、互いに独立した改善が順番に適用されるとすると、累積リフトは足し算ではなく掛け算で表せる。
ここで、 は 番目の改善の相対リフトである。
例えば、Hulu の推薦で、次の 5 つの改善が順に確認され、全てリリースされたとする。
候補生成の改善:
既視聴除外の改善:
公開終了作品の扱い改善:
推論レイテンシ改善:
棚タイトル改善:
このとき、累積倍率は次のようになる。
つまり、合計では約 2.01% の改善である。単純な足し算でも で近いが、厳密には改善は掛け算で累積する。
Hulu のような大規模サービスでは、2% の OEC 改善は小さく見えても、実際には非常に大きい可能性がある。例えば、視聴日数、継続率、解約率、広告付きプランの広告収益、TVOD 送客、カタログ消費の健全性などに波及するなら、事業インパクトは大きい。
Google 広告の例:大きな変更は多数の小さな実験から作られる
Google 広告の例では、改良された広告ランキングメカニズムが、1 年以上の開発と多数の実験を経て発表された。ここで重要なのは、最終的な変更が大きなバックエンド変更に見えても、その中身は多数のモデル改善、オークション設計の変更、広告主への影響確認、市場別の長期実験などで構成されている点である。
Hulu の推薦でも、大規模なランキング刷新は、単一の巨大実験としていきなり全体に出すべきではない。例えば、次のような要素に分解できる。
候補生成に協調フィルタリングを追加する。
avg_fingerprintによる内容類似候補を追加する。avg_mood_tagによる雰囲気類似を特徴量に入れる。新着作品や公開終了作品のブーストを調整する。
SVOD と TVOD の混合比率を制御する。
短尺エピソードと長尺映画の比較を正規化する。
キッズプロフィールでは安全性制約を強める。
これらを一度に入れると、勝っても負けても、どの要素が効いたのか分からない。したがって、実務では、小さな変更を個別に検証し、勝ったものを組み合わせ、その組み合わせを改めて検証する流れが必要である。
Bing 関連性チームの例:累積効果をどう信用するか
Bing の関連性チームは、単一の OEC を毎年 2% 改善することを目標にしていたと説明されている。この 2% は、1 年間にユーザーへ配信されたすべての実験の介入効果の総和、つまり累積効果として考えられている。
しかし、ここには重要な問題がある。多くの実験を実行すると、偶然に良く見える結果が必ず混ざる。例えば、有意水準 で 1,000 個の無効果な実験を行えば、期待値として約 50 個は偶然に有意に見える可能性がある。
したがって、Bing では、累積改善の信用度を確認するために、再実験や確認実験を重視している。あるアイデアが反復改善の末に有望になったら、最後に単一条件の確認実験を行い、その効果を目標達成への貢献として扱う。
Hulu の推薦でも同じである。例えば、候補生成の小変更を 100 本試せば、偶然に良く見えるものが出る。特に、セグメントをたくさん切ったり、メトリクスをたくさん見たりすると、「どこかで勝っている」結果は見つかりやすい。したがって、本当にリリースする前には、次のような確認が必要である。
仮説と OEC が事前に定義されていたか。
SRM やログ欠損がないか。
主要セグメントで極端な悪化がないか。
別期間や再実験でも同じ方向の効果が出るか。
複数の勝ち施策を組み合わせても効果が残るか。
効果を小さめに見積もる、つまり保守的に扱うことも実務上は有効である。例えば、初回実験で のリフトが出ても、確認実験やランプアップ計画では 程度の期待値として扱う方が、過大評価による意思決定ミスを避けやすい。
Bing 広告チームの例:改善パッケージと季節性
Bing 広告チームの例では、年間 15% から 25% の収益成長が、多くの小さな改善パッケージの積み重ねで達成されていたと説明されている。月ごとに実験結果をまとめたパッケージが出荷され、月によってはスペース制約や法的要件のためにパッケージがマイナスになることさえあった。
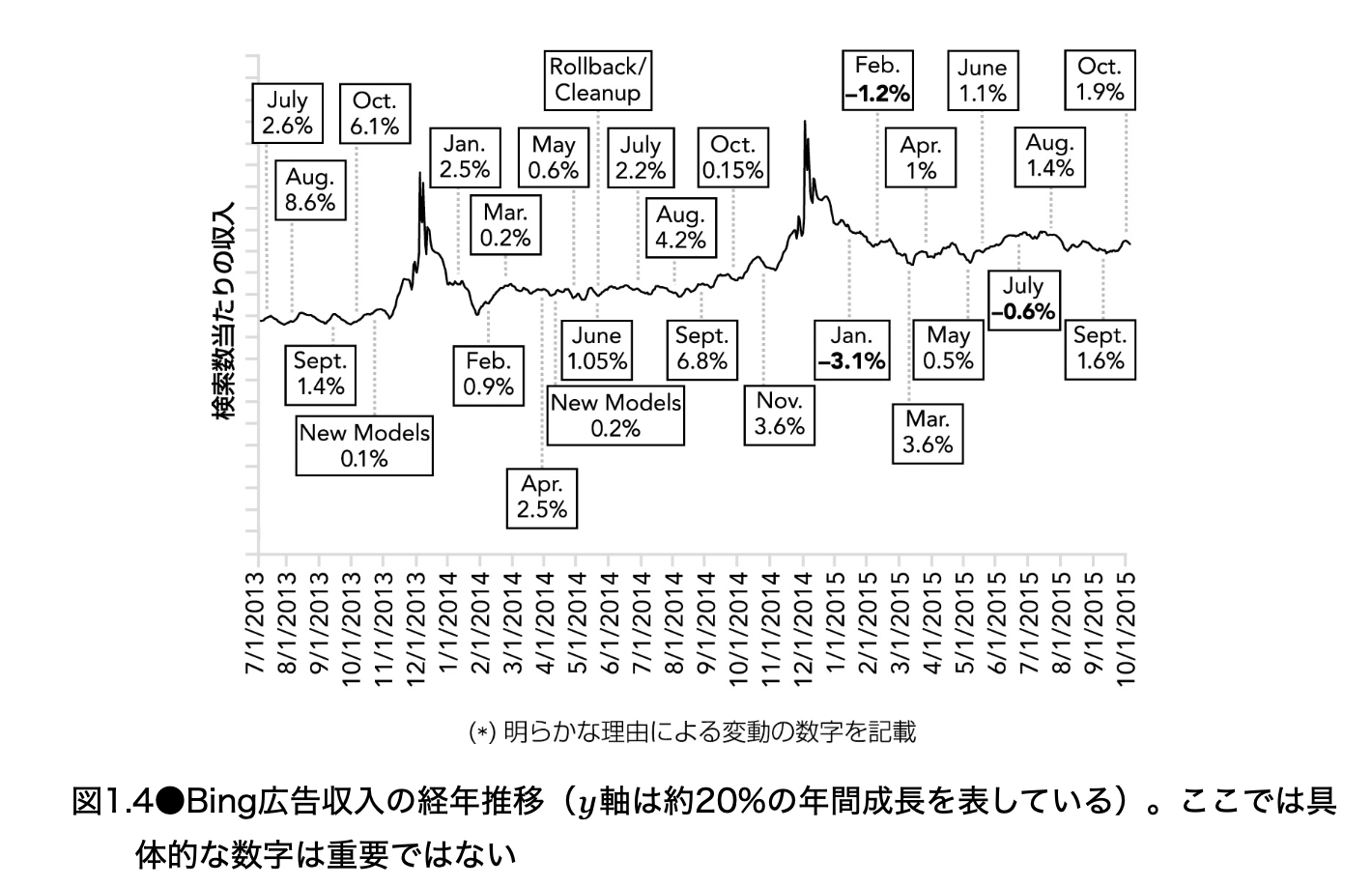
この図から読み取るべき点は、実験による改善と、季節性や外部要因を分けて考える必要があるということである。広告では 12 月に購買意欲が高まり、検索 1,000 件あたりの収益が上がりやすい。これは実験の効果ではなく、季節性である。
Hulu でも季節性は非常に重要である。例えば、年末年始、ゴールデンウィーク、夏休み、アニメ新クール開始時期、大型映画の配信開始、連休、卒業・入学シーズンなどで視聴行動は変わる。単純な前後比較では、推薦改善と季節性を混同しやすい。
したがって、継続的改善では、同時期に Control と Treatment を比較することが重要である。もし 12 月に視聴時間が増えたとしても、それが新しい推薦モデルのおかげなのか、単に休暇で視聴時間が増えたのかは、A/B テストでなければ判断しにくい。
興味深い実験とは何か
教科書は、興味深い実験を「予想していた結果と実際の結果の絶対的な差が大きいもの」と定義している。これは重要である。なぜなら、実験の価値は、単に勝ったか負けたかだけではなく、どれだけ学習を生んだかにもあるからである。
予想どおりの結果が出た実験は、意思決定には役立つが、学びは小さい。逆に、予想と違う結果が出た実験は、プロダクト理解を更新する機会になる。
Hulu の推薦で例を挙げる。
「視聴済み作品に似た作品を増やせば 25% 以上視聴が増える」と予想し、その通り少し増えた。これは良いが、驚きは小さい。
「似た作品を増やせば視聴が増える」と予想したが、実際には短時間離脱が増えた。これは、ユーザーが似た作品ばかりを好むわけではないことを示す重要な学びである。
「公開終了作品を少し上げても影響は小さい」と予想したが、特定ジャンルで大きく視聴が増えた。これは、見逃し回避ニーズが強いセグメントを発見した可能性がある。
「TVOD 作品を少し混ぜると収益が増える」と予想したが、SVOD 視聴や継続 proxy が悪化した。これは、短期収益とサブスクリプション体験のトレードオフを示す。
このように、驚きは次の仮説を生む。実験文化とは、勝った施策を探すだけではなく、予想外の結果からプロダクト理解を更新する仕組みでもある。
UI の例:41 段階の青
Google の「41 段階の青」の例は、小さなデザイン変更が大きな影響を持ち得ることを示している。色の微調整は、直感的には些細に見える。しかし、リンクの視認性、クリックしやすさ、信頼感、ユーザーがタスクを完了する速度に影響し得る。
Hulu で言えば、推薦棚の UI も同様である。例えば、次のような変更は小さく見える。
作品カードのタイトル文字サイズを少し変える。
サムネイル下のメタ情報を 1 行にするか 2 行にするかを変える。
「あなたにおすすめ」という棚名を変える。
視聴済みバッジや続きから再生の表示位置を変える。
公開終了が近い作品のラベルを出す。
これらはモデル改善ではないが、ユーザーの選択行動に大きく影響する可能性がある。推薦 ML エンジニアにとっても、モデルスコアだけでなく、推薦がどう表示されるかを理解することが重要である。なぜなら、最終的に観測される暗黙的フィードバックは、モデルの品質と UI の提示方法の両方に依存するからである。
ただし、教科書が指摘するように、一度広範囲に探索した領域では、追加改善の余地は小さくなる。色や余白のような領域は、初期には大きな改善が見つかるかもしれないが、最適化が進むほど限界効用は下がる。
適切なタイミングでのオファー
Amazon のクレジットカードオファーの例では、同じオファーでも、表示するタイミングを変えるだけで大きな効果が出た。ホームページに出すと関心が薄いユーザーが多く、CTR は低かった。一方、商品をカートに入れた直後のユーザーは購入意欲が高いため、節約額を具体的に示すオファーが刺さりやすかった。
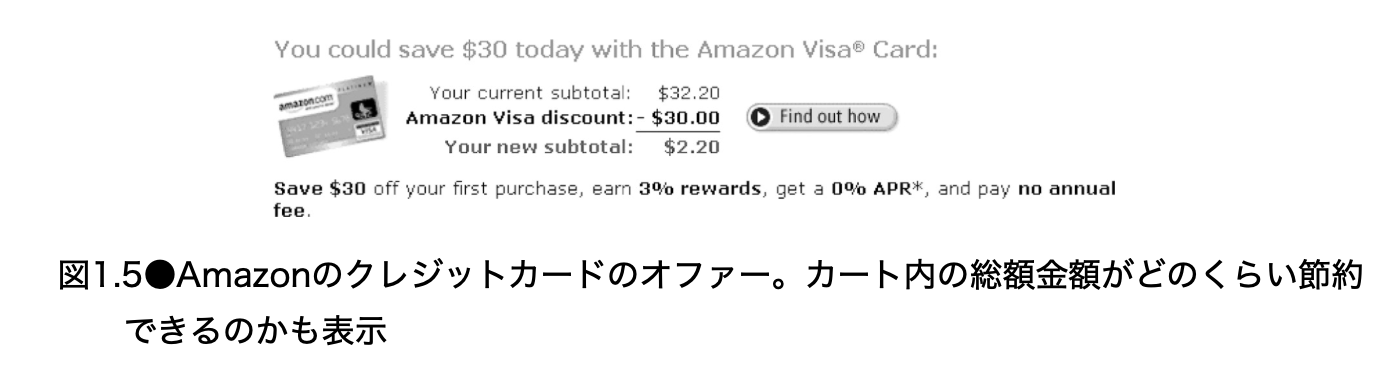
Hulu の推薦でも、「何を出すか」と同じくらい「いつ出すか」が重要である。例えば、次のようなタイミングの違いがある。
トップページを開いた直後に新作を出す。
1 エピソードを見終わった直後に次の関連作品を出す。
シリーズ完走直後に同じ出演者や同じ雰囲気の作品を出す。
公開終了が近い作品を、終了直前ではなく数日前から出す。
週末の夜に長尺映画を出し、平日の朝には短尺作品を出す。
同じ作品でも、ユーザーの文脈によって価値が変わる。暗黙的フィードバックでは、この文脈依存性が特に重要である。ある作品がクリックされなかったとしても、作品自体が悪いとは限らない。出すタイミング、棚位置、サムネイル、同時に並んでいた他作品、デバイス、ユーザーの時間制約が影響している。
パーソナライズされたリコメンド
Amazon のカート内リコメンドの例は、専門家の直感と実験結果が衝突する典型例である。マーケティング責任者は、購入直前にリコメンドを出すとユーザーの気が散り、購入完了を妨げると考えた。しかし、実験では大きく勝ち、カートリコメンドは緊急でローンチされた。
Hulu でも、似たような議論は起こり得る。例えば、ユーザーが作品詳細ページまで来た時点で、関連作品を出すべきかどうかを考える。ある人は「詳細ページではその作品への集中を邪魔すべきではない」と言うかもしれない。一方で、別の人は「その作品が合わなかったときの逃げ道として関連作品を出すべきだ」と言うかもしれない。
どちらの主張ももっともらしい。しかし、本当にユーザー体験を改善するかは測らなければ分からない。A/B テストでは、例えば次を比較できる。
Control: 作品詳細ページに関連作品を出さない。
Treatment A: 下部に関連作品を出す。
Treatment B: 再生ボタン付近には出さず、詳細説明の下に出す。
Treatment C: 視聴済み作品に基づく関連作品だけを出す。
OEC は、詳細ページからの再生開始率だけでは不十分である。関連作品によって元作品の再生開始が減っても、結果的に 25% 以上視聴シリーズ数や満足視聴が増えるかもしれない。逆に、関連作品クリックは増えても短時間離脱が増えるなら、体験は悪化している可能性がある。
多くのスピード問題
Bing のパフォーマンス改善の例は、速度が主要メトリクスに強く影響することを示している。10 ミリ秒の改善でさえ、規模が大きいサービスでは大きな価値を持つことがある。
Hulu の推薦でも、パフォーマンスは推薦品質の一部である。どれだけ良い作品を推薦しても、トップページ表示が遅い、棚が遅れて表示される、サムネイル読み込みが遅い、再生開始まで待たされる、という体験ではユーザーは離脱する。
推薦 ML
では、モデルを複雑にすると精度が上がる一方で、推論レイテンシが悪化することがある。例えば、ランキングに大量の特徴量を追加し、avg_fingerprint
の類似計算や mood tag
の再ランキングをリアルタイムで行うと、表示までの時間が伸びるかもしれない。
このとき、オフライン精度だけで判断すると危険である。例えば、NDCG@20 が 1% 改善しても、トップページ表示が 100 ミリ秒遅くなり、視聴開始率や 25% 以上視聴率が下がるなら、オンラインでは負ける可能性がある。
簡単な数値例を考える。新モデルで推薦経由の 25% 以上視聴率が、ランキング品質だけなら 改善すると期待される。しかし、レイテンシ悪化によりトップページ離脱が 増え、再生開始失敗や待ち時間による機会損失が 相当あるとする。粗い近似では、純効果は次のようになる。
まだプラスだが、期待よりかなり小さい。もしレイテンシ影響が なら、純効果はマイナスになる。
したがって、推薦実験ではモデル品質メトリクスだけでなく、レイテンシ、エラー率、タイムアウト率、フォールバック率を必ずガードレールとして見るべきである。
マルウェアの削減
教科書のマルウェア削減の例では、ユーザーがインストールしたフリーウェアが Bing の検索結果ページを改変し、広告を大量に追加していた。これは Microsoft の収益を奪うだけでなく、ユーザーに低品質な体験を与えていた。

Microsoft は DOM を修正する基本ルーチンを上書きし、信頼できるソースからの限定的な修正だけを許可する実験を行った。その結果、セッション数、検索成功率、クリックまでの時間、収益、ページロード時間など複数のメトリクスが改善した。
Hulu で直接マルウェアが同じ形で起こるとは限らないが、似た構造の問題はある。ユーザー体験を悪化させる外部要因やクライアント環境の問題が、プロダクト評価に混ざることがある。
例えば、次のような状況である。
特定のテレビデバイスだけサムネイル表示が遅い。
一部アプリバージョンで推薦棚の露出ログが欠損している。
ネットワーク品質が悪いユーザーで再生開始失敗が増えている。
広告付きプランで広告 SDK の遅延が推薦面の評価に影響している。
外部 CDN や画像配信の問題で作品カードが空白になる。
このような問題は、推薦モデルの良し悪しとは別に、ユーザーの行動と OEC を動かす。したがって、A/B テストでは、モデルだけでなく、ユーザーが実際に受け取った体験を測る必要がある。
バックエンド変更と推薦アルゴリズム
教科書は、バックエンドアルゴリズムの変更がコントロール実験の対象として見落とされがちだが、大きな結果を生むことがあると述べている。Amazon の behavior-based-search の例はその典型である。
Amazon で “24” と検索すると、従来手法では「24」という文字列に引っ張られて、24 曲入り CD、24 ヶ月用の服、24 インチのタオルバーなどが返っていた。一方、新しい手法では、「24」と検索した人が実際に買った商品に基づき、テレビ番組 “24” の DVD や関連商品を返した。

この例は、Hulu の検索・推薦に非常に近い。動画サービスでは、クエリや作品タイトルの文字列だけでは意図を取り違えることがある。例えば、「24」「コナン」「キングダム」「silent」「ドラゴン」などは、複数の作品、人物、ジャンル、一般語にまたがる可能性がある。
Hulu で behavior-based な考え方を使うなら、次のような情報が役立つ。
そのクエリで検索した profile が、その後 25% 以上視聴した series。
ある series を視聴した profile が、次に視聴した series。
ある作品詳細を見た profile が、最終的に再生した series。
avg_fingerprintやavg_mood_tagが近く、かつ視聴遷移も多い作品。
ただし、行動ベースの手法には注意点もある。人気作品に寄りやすい、過去の露出バイアスを増幅しやすい、新作やロングテール作品に弱い、検索語に含まれていない作品が出て説明しにくい、といった問題がある。Amazon の例でも、検索語に含まれていない商品が出ることが弱点として述べられている。
だからこそ、バックエンド変更はオフライン評価だけでなく、オンライン実験で検証する必要がある。検索や推薦では、ユーザーが意図した作品に早く到達できたか、25% 以上視聴に至ったか、検索を繰り返す必要が減ったか、短時間離脱が増えていないか、といった指標を見る必要がある。
戦略、戦術、実験の関係
この節の後半では、戦略と実験の関係が説明されている。重要なのは、実験は戦略の代わりではないということである。実験は、戦略を実行するための戦術を磨き、戦略が本当に機能しているかを学ぶためのフィードバックループである。
Hulu の推薦戦略を例にすると、次のように整理できる。
戦略: ユーザーが自分に合う作品を素早く見つけ、継続的に Hulu を使う理由を増やす。
OEC: 25% 以上視聴ユニークシリーズ数、複数日視聴、翌週再訪率などを組み合わせた長期価値 proxy。
戦術: 内容類似推薦、協調フィルタリング、公開終了作品ブースト、棚タイトル最適化、レイテンシ改善、キッズ安全性制約など。
実験: 各戦術が OEC を改善し、ガードレールを悪化させないかを検証する。
戦略がなければ、実験は局所的な数字遊びになりやすい。例えば、クリック率だけを上げる棚タイトルやサムネイルを最適化し続けると、短期クリックは増えても、視聴満足度や長期継続は悪化するかもしれない。
一方で、戦略だけがあり、実験がなければ、実行している戦術が本当に効いているか分からない。例えば、「発見体験を良くする」という戦略を掲げても、具体的に多様性をどれくらい増やすべきか、既視聴類似と新規性をどうバランスさせるべきかは、測らなければ分からない。
シナリオ 1:現在の戦略のもとで局所最適へ登る
シナリオ 1 は、すでに事業戦略があり、実験できる十分なユーザーがいる場合である。この場合、実験は現在の戦略のもとで局所最適へ登るために役立つ。
Hulu 推薦で言えば、すでに「ユーザーが観たい作品を短時間で見つけられるようにする」という戦略があり、OEC も定義されている状態である。このとき、実験は次のような意思決定に使える。
どの候補生成ロジックが OEC を最も改善するか。
どの棚位置が最も ROI が高いか。
どのセグメントで内容類似推薦が効くか。
レイテンシ改善にどれだけ投資する価値があるか。
大規模リデザインより、段階的な UI 改善の方がよいか。
特に重要なのは、完全なリデザインよりも継続的な改善が有効なことが多い点である。大規模リデザインは、ユーザーの慣れを壊す。旧 UI に慣れていたユーザーは、新 UI が長期的には良くても、短期的には迷いやすくなる。これがプライマシー効果や変化嫌悪である。
Hulu でトップページを全面的に変える場合、短期 A/B テストでは Treatment が負ける可能性がある。ユーザーが棚の位置や操作に慣れていないからである。このような実験では、短期 OEC だけでなく、学習期間、長期リテンション、デバイス別の使いやすさ、問い合わせ、検索への逃避などを慎重に見る必要がある。
OEC と Strategic Integrity
教科書では、OEC が戦略を明確にし、トップダウンの戦略とボトムアップの仕事を一致させる仕組みになると説明されている。これは Strategic Integrity の話である。
Hulu の推薦チームで考えると、OEC が明確であれば、各チームの小さな改善が同じ方向を向きやすい。
例えば、OEC が「推薦経由の 25% 以上視聴ユニークシリーズ数」だけだと、短期視聴を増やす施策に偏る可能性がある。そこで、複数日視聴、翌週再訪、短時間離脱、レイテンシ、キッズ安全性、作品多様性などを含めて、主 OEC とガードレールを設計する必要がある。
OEC は、次のような役割を持つ。
どの実験を成功とみなすかを決める。
どの施策に投資するかを比較可能にする。
チーム間の議論を主観ではなく共通指標に寄せる。
戦略に反する局所最適化を防ぐ。
ただし、OEC はゲーム化される危険がある。例えば、クリック率を OEC にすると、釣りタイトルや強いサムネイルでクリックだけ増やす方向へ進むかもしれない。再生開始数を OEC にすると、短尺や人気作ばかりを出す方向へ進むかもしれない。したがって、OEC は定期的に見直す必要がある。
ガードレールは「何をしないか」を決める
戦略とは、何をするかだけでなく、何をしないかを決めることでもある。教科書は、クルーズ船の安全や航空機事故の例を使って、ガードレールメトリクスの重要性を説明している。
ソフトウェアでは、クラッシュや重大なエラーが代表的なガードレールである。Hulu では、推薦 OEC が改善しても、次のような悪化があれば採用すべきではない。
アプリクラッシュ率が上がる。
再生開始失敗率が上がる。
トップページ表示レイテンシが悪化する。
キッズプロフィールで不適切な作品が増える。
TVOD への誘導が過度になり、SVOD 体験が損なわれる。
同一作品や同一ジャンルへの集中が強くなり、カタログ消費が偏る。
極端な例を考える。Treatment が 25% 以上視聴シリーズ数を 改善したが、クラッシュ率を ポイント悪化させたとする。もしクラッシュがユーザー体験に非常に大きな負の影響を持つなら、OEC の小さな改善よりもガードレール悪化を重く見るべきである。
意思決定を数式で表すなら、単純化した総合スコアを次のように考えられる。
ここで、 や は悪化をどれだけ重く見るかを表す重みである。実務ではこのような線形スコアだけで決めるとは限らないが、考え方としては「OEC が上がれば何でもよい」ではなく、「守るべきものを守ったうえで OEC を上げる」が正しい。
シナリオ 2:方針転換を検討する
シナリオ 2 は、プロダクトと戦略はあるが、実験結果が方針転換を示唆する場合である。シナリオ 1 が現在の丘を登る話だとすれば、シナリオ 2 は別の高い丘へ移るべきかを考える話である。
Hulu の推薦で言えば、現在の戦略が「過去視聴に近い作品をより正確に出す」だとする。この戦略のもとで、内容類似、同ジャンル、同出演者、同シリーズ、協調フィルタリングなどを改善してきた。しかし、何十本も実験しても OEC が伸びなくなったとする。
このとき、局所改善の余地が小さくなっている可能性がある。別の戦略、例えば「ユーザーの発見体験を広げる」「家族利用に最適化する」「短時間で選べる体験を作る」「ライブや新着への導線を強める」などに方針転換する必要があるかもしれない。
ただし、大きなジャンプは失敗しやすい。サイトの大規模再設計や推薦思想の大変更は、短期的にユーザーを混乱させる可能性がある。したがって、急進的なアイデアは、MVP として小さく試し、実験で不確実性を減らすべきである。
急進的なアイデアでは実験設計が変わる
急進的なアイデアを試すときは、通常の小さな A/B テストとは注意点が変わる。
第一に、実験期間を長くする必要がある場合がある。大きな UI 変更では、最初はユーザーが慣れておらず、短期メトリクスが悪化することがある。もし長期的には良い体験でも、1 週間の実験では負けに見えるかもしれない。
第二に、十分な規模が必要な場合がある。両面市場やネットワーク効果がある領域では、小さな Treatment では市場全体が変わらない。Hulu でも、例えばランキングに「現在話題の作品」を強く反映する施策は、十分なユーザー行動が集まらないと本来の効果が出ないかもしれない。
第三に、複数の戦術を試す必要がある。戦略が正しくても、最初の戦術が悪ければ実験は負ける。例えば「作品発見を広げる」という戦略自体は有望でも、単に多様性をランダムに増やすだけでは負けるかもしれない。棚タイトル、表示位置、探索導線、説明文、パーソナライズ強度などを複数試す必要がある。
サンクコストと達成された失敗
教科書では、Bing がソーシャルネットワーク統合に 2 年間取り組んだが、主要メトリクスに価値を見出せず放棄した例が紹介されている。これは、サンクコストを無視して将来を見た判断をすべきだという話である。
Hulu でも、大きな推薦基盤刷新や UI 改修に多くの時間を使った後で、実験結果が悪いことはあり得る。このとき、「ここまで作ったのだから出したい」と考えるのは自然である。しかし、過去に使ったコストは戻らない。重要なのは、これから全ユーザーに出すことで将来の OEC が改善するかどうかである。
Eric Ries の「達成された失敗」とは、間違った計画を、予定通り、品質高く、忠実に実行してしまうことである。計画達成そのものを成功とみなすと、主要メトリクスが改善していなくても成功宣言できてしまう。A/B テストは、この危険を避けるための現実チェックである。
情報の期待値 EVI
最後に、情報の期待値、つまり Expected Value of Information という考え方が出てくる。これは、「追加で情報を得ることが、意思決定にどれだけ価値を持つか」を考える概念である。
簡単な例を考える。Hulu で新しい推薦 UI を全体展開するか迷っているとする。全体展開により、成功すれば年間価値が 5 億円、失敗すればユーザー体験悪化や開発運用コストで 2 億円の損失になるとする。現時点では成功確率を と見積もっている。
実験なしで出す場合の期待値は次のようになる。
単位を億円とすれば、期待値は 0.8 億円である。
ここで、MVP 実験に 0.2 億円かかるが、成功確率の見積もりをかなり改善できるとする。実験によって悪い案を止められる可能性が高いなら、その情報には価値がある。たとえ実験コストがかかっても、全体展開の不確実性を下げることで、意思決定の期待値を改善できる。
この考え方は、推薦 ML の実務に非常に合う。オフライン評価だけではオンライン効果が分からない場合、小さなランプアップ実験によって不確実性を減らす。全ユーザーに出す前に、期待値がプラスか、ガードレールが壊れていないか、どのセグメントで効くかを学ぶのである。
Hulu 推薦での実務チェックリスト
この節の内容を、Hulu の推薦開発で実験を回すときのチェックリストにすると、次のようになる。
改善は小さく見えても、対象範囲による希釈を考慮して評価する。
全体 OEC だけでなく、事前に定義した対象セグメントでの効果も見る。
多数の実験から偶然の勝ちが出るため、確認実験や再実験を重視する。
季節性、公開開始、公開終了、連休、アニメ新クールなどの外部要因を前後比較で解釈しない。
UI、タイミング、パフォーマンス、バックエンドアルゴリズムをすべて実験対象として扱う。
オフライン評価で勝った推薦モデルでも、レイテンシや短時間離脱を含めてオンラインで確認する。
OEC を戦略と接続し、クリック率や再生開始数だけのゲーム化を避ける。
ガードレールを事前に定義し、クラッシュ、再生失敗、キッズ安全性、レイテンシ悪化を許容しない。
大きな戦略変更は MVP で小さく試し、実験期間や規模を通常実験より慎重に設計する。
サンクコストではなく、将来の OEC とユーザー価値でリリース判断を行う。
まとめ
継続的な改善とは、単にたくさん実験することではない。小さな改善を信用できる形で測り、偶然の勝ちを排除し、季節性や外部要因を切り分け、OEC とガードレールに基づいて意思決定し、学びを次の仮説へつなげることである。
Hulu の動画推薦では、暗黙的フィードバックである 25% 以上視聴、視聴日数、再訪、検索行動、短時間離脱、完走、レイテンシなどを使って、モデルとプロダクト体験の両方を評価する必要がある。推薦 ML の改善は、候補生成やランキングの精度だけでは完結しない。表示タイミング、UI、速度、デバイス、作品カタログ、セグメント、事業戦略まで含めた総合的な体験として評価される。
そして、実験は戦略の代わりではなく、戦略を現実に接続するフィードバックループである。良い OEC は、トップダウンの戦略とボトムアップの改善を結びつける。一方で、実験結果が戦略の限界を示すなら、方針転換を検討する必要がある。小さく試し、学び、積み上げ、必要なら方向を変える。このサイクルこそが、信用できるデータドリブンな改善の実体である。