ch2-2 仮説検定:偶然の差と介入効果を区別し、実験を設計する
この節の主題は、A/B テストで観測した群間差を見て、それが偶然のばらつきで十分に説明できるのか、それとも介入による効果と考えるのが妥当なのかを判断する方法である。ここでいう仮説検定は、変更が「必ず効いた」と証明するための手続きではない。ランダム割当、計測、分析が適切であるという前提の下で、 効果がゼロであるという仮定と、得られたデータがどの程度整合しないか を定量化する手続きである。
Hulu の推薦 ML では、モデル A とモデル B のオフライン指標の差だけでリリースを判断できない。ランキングの変更は、作品カードの表示、選択、再生開始、一定時間以上の視聴、継続視聴、後日の再訪問という一連の行動を通じて初めて価値になる。また、同じ変更でも profile、デバイス、曜日、配信作品の状況によって観測値が揺れる。したがって、実験の前に「どのくらい揺れるメトリクスなのか」「どの大きさの差なら事業上意味があるのか」「その差を見つけるには何人・何日が必要か」を定める必要がある。
この節は、次の順に読むと整理しやすい。
メトリクスには平均的な水準と、推定値の不確実性がある。
帰無仮説、p 値、信頼区間は、同じ群間差を異なる形で表す。
統計的有意性と実用的有意性は別物である。
検出力と最小検出可能効果を先に決めて、必要標本数と期間を設計する。
Hulu のような継続サービスでは、割当単位、分析対象、曜日、季節性、ノベルティ、他実験との干渉を同時に扱う。
まず何を比較しているのか
コントロール群を 、介入群を とする。各 profile に対して、あらかじめ定義した分析期間内のメトリクス を一つ計算する。例えば、ホーム画面の推薦ランキングを変更する実験では、次のような を取り得る。
7 日間の総視聴秒数。
7 日間に 25% 以上視聴したユニークシリーズ数。
推薦棚からの再生開始有無。
視聴開始後に一定割合まで到達したかどうか。
hj-data-01.report.content_viewing には profile
ごとの視聴イベントと watched_seconds
があり、hj-data-01.report.unique_viewed_series
には、動画コンテンツ長の 25% 以上を視聴した series が profile
ごとに記録される。後者は、単なるインプレッションやタップより強い暗黙的フィードバックとして利用できる。一方で、どの推薦棚から来た視聴かを判定するには、hj-data-01.intermediate.ga4_unnested_cleaned_log
の
event_name、event_params_tray_area_name、event_params_tray_order、event_params_series_id
など、露出・選択のイベント定義と結合条件を別途確認する必要がある。
各群の標本平均を次のように置く。
実験で観測する絶対差の推定値は、通常、次である。
報告では、ベースラインに対する相対差も併記することが多い。
ただし、検定と信頼区間は基本的には絶対差 を対象に計算し、その後で解釈しやすい相対差に換算すると分かりやすい。分母の平均が非常に小さいと、相対差は不安定になるためである。
ワークド例:profile ごとの視聴シリーズ数から群間差を作る
ホーム画面の「アニメへのおすすめ」棚について、現行ランキングを control、新ランキングを treatment とする。説明を単純にするため、各群 5 profile の「7 日間に 25% 以上視聴したユニークシリーズ数」が次の通りだったとする。例えば、ある profile が『葬送のフリーレン』を 25% 以上視聴し、その後『SPY×FAMILY』も 25% 以上視聴したなら、その profile の値は 2 である。
| 群 | profile ごとの | 合計 | 人数 |
|---|---|---|---|
| Control | |||
| Treatment |
このとき、群ごとの平均は次の通りである。
したがって、絶対差と相対差は次のように計算できる。
この小標本の 37.5% は、すぐに「新モデルの効果」とは言えない。たまたま Control 群にほとんど視聴しない profile が入っただけでも、この程度の差は起こり得る。ここから先で標準誤差を計算するのは、この 0.6 本という差が profile 構成の偶然を考慮しても十分に大きいかを判断するためである。
ここで最も大事なのは、同じプロダクトを見ても、個々の profile の は大きく異なる点である。ある profile は数時間視聴し、別の profile はまったく視聴しない。偶然にもヘビーユーザーが一方の群に多く入れば、介入が無効でも平均視聴秒数に差が出る。仮説検定が扱うのは、このようなランダムな群構成の違いによって生じる差である。
ベースライン平均、標準偏差、標準誤差
ベースライン平均は「今の水準」である
実験開始前の過去データ、または A/A テストから得るメトリクスの平均をベースライン平均という。例えば、対象 profile における 7 日間の平均視聴秒数が 8,000 秒なら、ベースラインは 8,000 秒である。
ベースラインは、相対 MDE を絶対値に直すために必要である。「1% の改善を検出したい」は、絶対差にすると次のようになる。
この 80 秒は、統計的に検出したい最小の絶対効果であり、後述する MDE の一部になる。ただし、平均が同じ 8,000 秒でも、profile 間の視聴時間のばらつきが違えば、必要標本数は全く異なる。
ワークド例:1% が視聴体験として何を表すか
Control 群の平均が 8,000 秒、Treatment 群の平均が 8,080 秒だったとする。Treatment 群では、例えば『僕のヒーローアカデミア』のエピソードを 80 秒多く見た profile が平均的に増えた、という集計上の差である。差と相対差は次の通りである。
ただし、この 80 秒は「すべての profile が 80 秒ずつ長く見た」ことを意味しない。新ランキングによって再生を始める profile が少し増えた結果、全 profile 平均で 80 秒増えた可能性もある。平均は、個々の効果の分布を一つに要約した値である点に注意する。
標準偏差は「個々の値の散らばり」である
1 profile あたり 7 日視聴秒数の標準偏差を とする。標準偏差が大きいとは、profile ごとの値が平均から大きく離れていることを意味する。視聴秒数は、ゼロが多く、長時間視聴する少数の profile が上側の裾を引くため、典型的に分散が大きいメトリクスである。
一方、「7 日以内に 25% 以上視聴を 1 本でもしたか」という二値指標なら、値は 0 または 1 だけである。成功確率を とすれば、その標準偏差は次である。
このため、収益額や総視聴時間のような連続量より、購入有無・再生開始有無のような二値メトリクスのほうが標準誤差が小さくなることがある、というのが本文の趣旨である。ただし、二値指標のほうが常に良いわけではない。二値化すると「どれだけ視聴したか」「高品質な視聴だったか」という情報を捨てる。OEC は、感度だけでなく、事業価値をどの程度正しく代理するかで選ぶ必要がある。
ワークド例:25% 視聴有無を 0/1 にする
対象 profile の 40% が、7 日以内に少なくとも 1 シリーズを 25% 以上視聴するとする。このとき、各 profile の二値メトリクスを、視聴したなら 1、しなければ 0 と置けば、 である。profile 単位の標準偏差は次になる。
各群 2,500 profile なら、各群における「25% 以上視聴率」の標準誤差は次である。
すなわち、各群の視聴率の推定誤差の規模は約 0.98 percentage points である。ここで Treatment の視聴率が 42%、Control が 40% なら、観測差は 2 percentage points である。この差を有意といえるかは、二群の平均との差の標準誤差を使って次で判定する。
標準誤差は「平均の推定値の揺れ」である
標準偏差と標準誤差は混同されやすいが、対象が異なる。
標準偏差は、profile ごとの のばらつきである。
標準誤差は、同じ条件で実験を何度も繰り返したときの標本平均 のばらつきである。
独立な profile を 人抽出し、その標準偏差を と推定したとき、平均の標準誤差は概ね次である。
標本数を 4 倍にしても、標準誤差は半分にしかならない。したがって、精度を少し上げるために必要なトラフィックは急速に増える。これが「小さな差を検出するほど高コストになる」理由である。
比較したいのは二群の平均差である。群が独立であれば、平均との差の標準誤差は次である。
過去データから両群の分散がほぼ等しいと見込め、等配分なら 、 と近似できる。このとき、
となる。本文で「平均の標準偏差が低いほど感度が上がる」と書かれている箇所は、厳密には、この平均との差の標準誤差が小さいほど、同じ効果をゼロから区別しやすいという意味である。
ワークド例:二群の標準誤差を計算する
7 日間の総視聴秒数について、過去データから各群の標準偏差がともに 秒と見込まれ、Control と Treatment に各 profile を割り当てたとする。このとき、平均との差の標準誤差は次になる。
つまり、観測差が 50 秒程度なら、ランダム割当だけでも生じ得る揺れと同程度である。一方、観測差が 200 秒なら、標準誤差の約 4 倍であり、偶然だけで説明しにくくなる。この段階ではまだ p 値を計算していないが、差を標準誤差で割る考え方が、次節の検定統計量そのものである。
Hulu の例:なぜ長く回しても効率が落ち得るのか
7 日総視聴秒数のような累積メトリクスでは、期間を 14 日に延ばすと、各 profile の視聴秒数も増える。しかし、平均だけでなく、ユーザーごとの累積値のばらつきも大きくなり得る。例えば、週末にだけ長時間視聴する profile、毎日短く視聴する profile、1 週目だけ視聴する profile が混ざるためである。
また、日数を延ばしてもユニークな profile 数は日数に比例して増えない。初日に来た profile の一部が翌日以降も戻るため、2 日目に増えるのは「初日にいなかった新規 profile」とリピート profile の一部である。リピート profile を新しい独立標本として数えることはできない。さらに、同じ profile を日別行として扱って独立な観測値であるかのように t 検定をすると、相関を無視して標準誤差を過小評価し、有意差が出やすくなる。
したがって、ユーザーランダム化の推薦実験では、原則として「割り当てられた profile ごとに、実験期間全体のメトリクスを 1 値に集約する」分析が安全である。日別の効果推移を見たい場合は、日ごとの profile 集合の重複と profile 内相関を意識して、推定方法を別途設計する。
帰無仮説と対立仮説
仮説検定では、まず比較対象を明示する。群の母平均を 、 とすると、両側検定の帰無仮説と対立仮説は次である。
帰無仮説 は「今回の介入には平均的な効果がない」という基準モデルである。対立仮説 は「正または負の差がある」である。推薦変更は視聴を改善する意図で始めることが多いが、悪化も重要な結果である。したがって、標準的なプロダクト実験では、あらかじめ強い根拠がない限り両側検定を使うのが普通である。
片側検定なら、例えば次の形である。
片側検定は、同じ標本数で改善を検出しやすい。しかし、悪化を「検定対象外」として扱う設計を事前に正当化できることは少ない。実験開始後に有意になりそうな側だけを選ぶことは許されない。片側・両側、主要メトリクス、分析期間、除外条件は、割当結果を見る前に決める必要がある。
ワークド例:仮説は「モデルが良い」ではなく平均差で書く
新ランキングが『名探偵コナン』や『薬屋のひとりごと』を適切に出せるという期待があっても、検定する仮説を「新モデルは良い」とは書けない。例えば主要 OEC を「7 日間に 25% 以上視聴したユニークシリーズ数」と決めたなら、検定しているのは次の命題である。
これは「新モデルを割り当てられた eligible profile の平均 OEC と、現行モデルを割り当てられた eligible profile の平均 OEC に差はない」である。結果が 本/profile だったとしても、帰無仮説は「個々の profile で必ず効果がゼロ」という意味ではない。正負の個別効果を平均するとゼロである場合も含む。実験で直接推定するのは、定義した母集団における平均処置効果である。
p 値が答える問いと、答えない問い
p 値の定義
帰無仮説が正しい、すなわち真の差がゼロであると仮定する。このとき、今回観測した差 と同程度か、それより極端な差が偶然に出る確率が p 値である。二群平均差では、概念的には次の検定統計量を作る。
大標本では、この は帰無仮説の下でおおむね標準正規分布に従う。小標本で分散未知の場合には、通常 Welch の t 検定を使い、t 分布で評価する。大規模なオンライン実験でも、極端な歪み、分母が小さい比率、cluster 単位の割当などでは正規近似の妥当性を確認すべきであり、単に行数が多いから問題がないとは限らない。
両側検定の p 値は、標準正規分布の累積分布関数を として、近似的に次のように表せる。
例えば、観測差が 秒、標準誤差が 秒なら、
であり、両側 p 値はおよそ 0.008 となる。これは「真の効果がゼロなら、今回と同程度以上に大きい絶対差を偶然に観測する確率は約 0.8%」という意味である。
ワークド例:視聴秒数の差から p 値までを一続きで計算する
Control と Treatment にそれぞれ 10,000 profile を割り当て、7 日間総視聴秒数の平均が次のようになったとする。
| 群 | profile 数 | 平均 7 日視聴秒数 | 標準偏差 |
|---|---|---|---|
| Control | 10,000 | 8,000 秒 | 3,600 秒 |
| Treatment | 10,000 | 8,136 秒 | 3,600 秒 |
まず、平均差は次である。
前節と同じ計算から、平均との差の標準誤差は約 50.9 秒である。よって、検定統計量は次になる。
標準正規分布では、 より右側に出る確率はおよそ 0.0038 である。両側検定では正側と負側の両方を「極端」と数えるため、2 倍して次になる。
この例では なので、5% の両側検定では帰無仮説を棄却する。ただし、結論は「新モデルによる平均視聴秒数の差がゼロであるというデータとの整合性は低い」であって、「すべての profile がより満足した」でも「136 秒という効果が確定した」でもない。
p 値が意味しないこと
p 値は、次の確率ではない。
「帰無仮説が正しい確率」が 0.8% という意味ではない。
「介入が効いている確率」が 99.2% という意味ではない。
「今回の結果が偶然である確率」が 0.8% という意味ではない。
「別の実験でも同じ結果が再現する確率」が 99.2% という意味ではない。
p 値は、帰無仮説を真と置いた条件付きの確率である。実験実装のバグ、SRM、計測漏れ、群間の露出差、他の同時施策、何度も途中集計して都合のよい時点で止める行為は、p 値の前提を崩す。p 値が小さいことだけから因果効果を主張できるわけではない。
有意水準 5% の正確な解釈
有意水準を と定め、p 値が 0.05 未満なら帰無仮説を棄却する、というルールを採用する。このルールを、実験開始前に決めた同じ設計で何度も適用したとき、真の差がゼロである実験を誤って「差がある」と判定する長期的な頻度は最大 5% である。これが第一種過誤の制御である。
したがって、「本当に効果がないなら、100 回中 95 回は効果があると言わない」という説明は、反復実験における頻度の説明として読むべきである。今回一回の実験について、「95% の確率で正しい判定である」とは言えない。また、5% は自然法則ではなく、偽陽性のリスクと検出力・コストのトレードオフを表す慣習的な基準である。安全性に関わる変更、非常に多数の候補を同時に評価する場合、あるいは大きな意思決定を伴う場合には、より厳しいしきい値、複数比較補正、追試を必要とすることがある。
ワークド例:100 回の実験というたとえを正しく読む
真の効果がまったくない同種のランキング変更を 100 個考える。それぞれで両側 5% 検定を一回ずつ行うなら、ランダムなばらつきだけで p 値が 0.05 未満になる変更が、平均的には約 5 個現れる。この 5 個は「偶然の当たり」であり、実装が間違っていなくても発生する。
したがって、候補モデルを 100 個オフラインで選び、その中から p 値が最小の 1 個だけを「有意だった」と報告することは危険である。100 回のうち 1 回の検定をした、という前提ではなく、多数の候補を探索したという事実を統計設計に入れる必要がある。これは、複数比較と実験前の候補固定が重要である理由である。
信頼区間:差の大きさと不確実性を同時に示す
大標本で正規近似が適切であれば、平均差の 95% 信頼区間は次で近似できる。
図 2.3 は、p 値による見方と 95% 信頼区間による見方が、両側検定・有意水準 5% では同じ結論に至ることを示している。
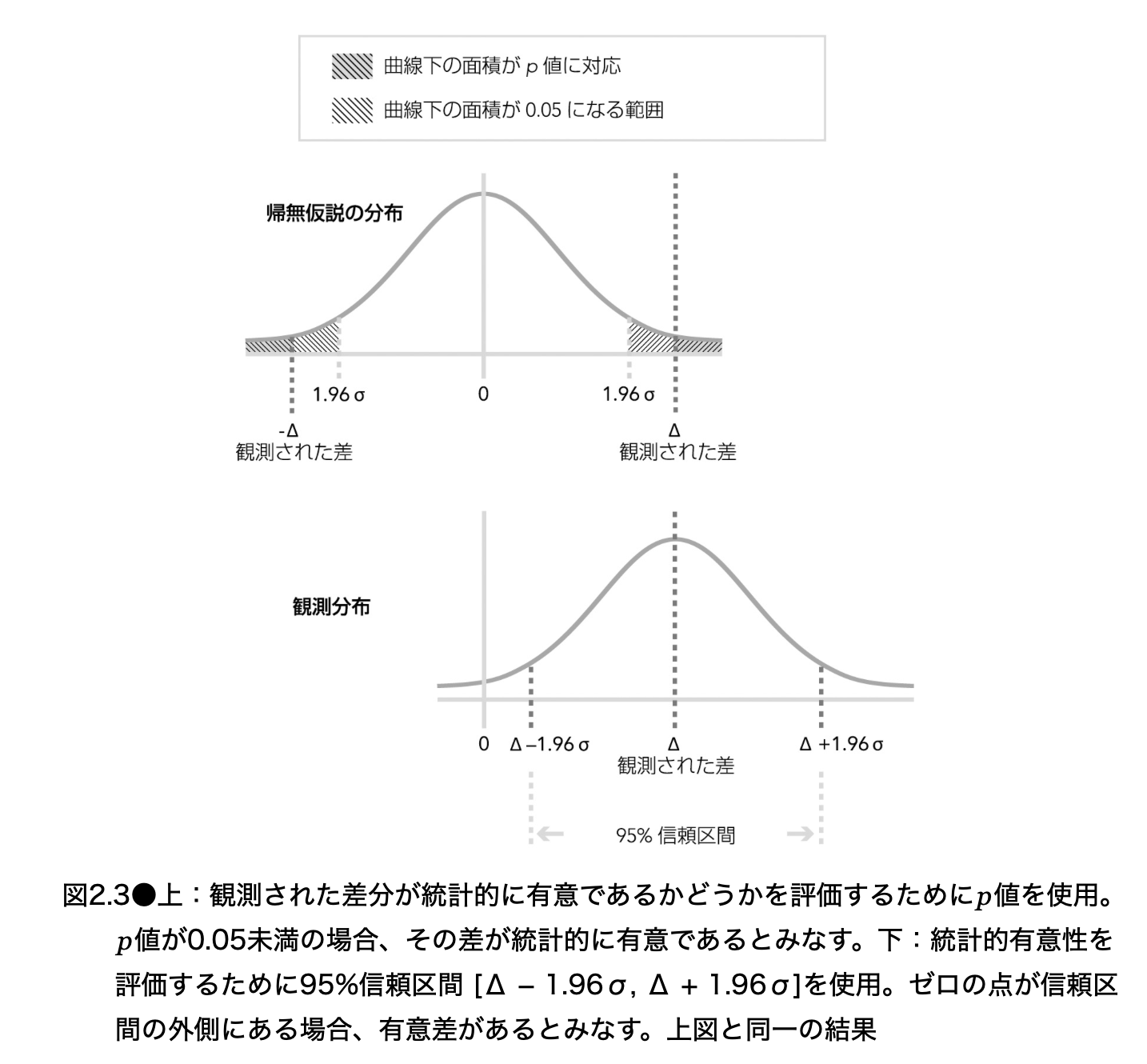
例えば、観測差が 80 秒、標準誤差が 30 秒なら、95% 信頼区間はおよそ次になる。
ゼロが区間に含まれないため、両側 5% 検定では統計的有意である。同時に、この実験から整合的と考えられる真の平均効果の範囲は、概ね 21 秒から 139 秒程度であると読める。p 値だけよりも、信頼区間のほうが「改善の大きさがどの程度あり得るか」と「推定の精度」を読み取れる。
ワークド例:同じ p 値の結論でも、採用判断は異なり得る
前節の Control 8,000 秒、Treatment 8,136 秒の例に戻る。平均差 136 秒、標準誤差 50.9 秒なので、95% 信頼区間は次の通りである。
これは相対差ではおよそ次の範囲になる。
統計的には正の効果である。しかし、事前に定めた実用下限が 1% 、すなわち 80 秒だったなら、区間下限の 36.2 秒はその下限を下回る。この実験は「効果が正である」ことを支持しても、「少なくとも 1% の改善がある」とまでは支持しない。追加コストが小さい UI 変更なら段階展開を選び得るが、高価なオンライン推論基盤への置換なら、同じ p 値でも判断は変わる。
ただし、95% 信頼区間を「今回計算した区間に真値が入る確率が 95%」と解釈するのは、頻度主義の定義としては正確ではない。同じ方法で実験と区間作成を無数に繰り返せば、そのうち 95% の区間が真の固定値を含む、という意味である。実務上は、「この手続きで得た効果のもっともらしい範囲」と読めば十分だが、確率の向きは意識しておくべきである。
図 2.3 の読み方
図の縦線の位置は観測差、横棒はその不確実性の範囲を表すと考えるとよい。
95% 信頼区間が正側だけにある場合、改善方向の統計的有意差である。
95% 信頼区間が負側だけにある場合、悪化方向の統計的有意差である。
95% 信頼区間がゼロをまたぐ場合、効果がゼロである可能性を棄却できない。
最後の場合は、「効果がないことを証明した」わけではない。小さい改善、小さい悪化、あるいはゼロが、データの不確実性の中で区別できていない状態である。とりわけ、区間が広いなら、単に標本数が足りない可能性が高い。
統計的有意性と実用的有意性を分ける
標本数が非常に大きければ、たとえ微小な差でも統計的有意になり得る。逆に、事業上は十分重要な差でも、標本数が少なければ統計的有意にならない。したがって、出稿判断は p 値だけではできない。
実用的有意性とは、その変更を実装・運用・保守し、他の機会を諦めてでも採用する価値がある効果の大きさである。これを最低限意味のある効果、すなわち minimum practical effect として実験前に決める。検出力分析で使う MDE は、通常、この実用的な最小効果を統計的に検出できるよう設定する。
例えば、ホーム推薦の新ランキングについて、OEC を「7 日間の 25% 以上視聴ユニークシリーズ数」とする。ベースラインが 2.00 本/profile で、0.02 本/profile、すなわち 1% の改善を実用上の下限と決めるとする。この 0.02 本の価値は統計からは決まらない。次のようなプロダクト上の根拠で決める。
推薦モデルの推論コスト、特徴量基盤、監視、オンコール負荷。
増えた 25% 視聴が、総視聴時間、継続視聴、解約抑制にどの程度つながるかという過去の知見。
既存モデルを置き換えることで失う安定性や、カタログ偏在・多様性低下のリスク。
他の施策で同程度の改善を得る機会費用。
実用的な下限を 本とするなら、信頼区間を使った判断は次のように精密にできる。
| 95% 信頼区間 | 解釈と判断例 |
|---|---|
| ゼロを含まず、実用下限 も上回る。改善の根拠が強い。 | |
| 統計的には正の差だが、実用下限を下回る効果もあり得る。段階展開や追加検証を検討する。 | |
| ゼロを含み、実用上の改善も確認できない。不確実であり、勝ちとは言えない。 | |
| 悪化方向で、実用的な損失も示唆される。原則として採用しない。 | |
| 実用上重要な改善・悪化の両方をおおむね除外できる。差がないことを支持したい場合は、等価性検定または非劣性検定を事前計画する。 |
最後の行は重要である。通常の「差があるか」の検定で p 値が大きいことは、同等性の証拠ではない。「悪化していない」「既存モデルと実質的に同じ」と主張したいなら、許容する差の幅を事前に定め、それに対応する等価性・非劣性の設計が必要になる。
検出力:本当にある効果を見逃さない確率
第一種過誤と第二種過誤
仮説検定の判断には、二種類の誤りがある。
| 実際の状態 | 帰無仮説を棄却しない | 帰無仮説を棄却する |
|---|---|---|
| 真の効果がゼロ | 正しい判断 | 第一種過誤。存在しない効果をあると判定する。確率は 。 |
| 真の効果がある | 第二種過誤。効果を見逃す。確率は 。 | 正しい検出。確率は 、すなわち検出力。 |
検出力は、事前に定めた大きさの真の効果があるときに、統計的有意差として検出できる確率である。
80% の検出力とは、真の効果がちょうど設計上の MDE である実験を、同じ設計で繰り返したなら、約 80% で有意差として検出できるという意味である。今回の一度の結果が 80% の確率で正しいという意味ではない。
検出力が低い実験の問題は、有意差が出にくいだけではない。偶然有意になったときに効果量が過大に見えやすい。これは winner’s curse と呼ばれる現象である。小標本の実験で「大勝ち」が出たときほど、効果の再現性と信頼区間の幅を慎重に見る必要がある。
ワークド例:80% の検出力は 10 回中 8 回という意味である
真の効果が、設計上の MDE である「7 日視聴秒数 +120 秒」であると仮定する。ここで検出力 80% の実験設計を 10 回、独立に繰り返したと考える。
平均的には約 8 回で、p 値が 0.05 未満となり「差あり」と検出する。
平均的には約 2 回で、p 値が 0.05 以上となり、真に +120 秒の効果があっても見逃す。
後者は実験やモデルが必ず失敗したことを意味しない。ランダムな群構成によって、観測差が小さく出た結果である。一度の実験が非有意だったときに必要なのは、まず「この実験はどの大きさの効果を 80% の確率で検出できる設計だったか」を確認することである。例えば、+120 秒を検出する設計なのに +20 秒の小効果を期待して非有意だったことを失敗と呼ぶのは、設計の読み違いである。
標本サイズに効く四つの変数
二群・等配分・両側検定・分散がほぼ等しいという単純化の下では、各群に必要な標本サイズは概ね次で近似できる。
ここで、 は profile 単位メトリクスの標準偏差、 は検出したい最小絶対差、 は有意水準、 は検出力である。この式から、次の関係が分かる。
メトリクスのばらつき が大きいほど、必要標本数は二乗で増える。
検出したい差 を半分にすると、必要標本数は約 4 倍になる。
有意水準を 5% から 1% に厳しくすると、必要標本数は増える。
検出力を 80% から 90% に上げると、必要標本数は増える。
例えば、両側 、検出力 80% では 、 である。7 日視聴秒数の標準偏差を仮に 秒、検出したい差を 秒と置くと、各群の必要標本数の粗い近似は次である。
これはあくまで概算である。実務では、過去の同じ母集団・同じ集計窓の分散、欠測、複数群、CUPED などの分散削減、cluster 化、分母が介入後に変わる比率指標を考慮した方法で算出する。とはいえ、差を半分にしただけで必要標本数が約 4 倍になるというオーダー感は、実験の優先順位を決める上で極めて有用である。
ワークド例:検出したい効果を半分にすると、何人必要になるか
同じく 秒、両側 5%、検出力 80% のまま、検出したい差を 120 秒ではなく 60 秒に下げる。このとき分母の は次のように変わる。
60 秒の二乗は 120 秒の二乗の 4 分の 1 であるため、必要標本数は 4 倍になる。
つまり、0.75% 程度の改善を 1% 程度の改善より精密に見分けたいだけでも、各群で約 15.7 万 profile が必要になる。この差は、推薦モデルの改善を実験する際に、「小さくても価値がある改善」を追うためのトラフィックと期間の費用を具体化する。
MDE は「実験後に得られる数値」ではない
MDE は Minimum Detectable Effect、すなわち、指定した 、検出力、標本数、ばらつきの下で検出できる最小効果である。MDE は実験前に決める設計パラメータであり、実用的な最小効果と整合させる。
トラフィックが限られ、計画期間内で MDE が実用下限より大きくなってしまうなら、その実験では「意思決定に必要なほど小さな差」を見分けられない。解決策は次のいずれかである。
より大きい実用効果だけを対象にする。ただし、価値のある小効果を見逃すことを受け入れる判断である。
対象母集団を、介入に事前に露出し得る profile に限定する。
より分散の小さい、かつ意思決定に整合するメトリクスに置き換える。
事前共変量を使う分散削減、例えば CUPED を使う。
期間またはトラフィック配分を増やす。
大きな一発実験ではなく、より強い仮説を持つ施策に絞る。
「有意にならなかったので効果なし」と結論する前に、計画時点の MDE と、実際に得られた信頼区間が、実用上重要な効果を除外できるほど狭いかを確認すべきである。
ワークド例:MDE と実用下限がずれると何が起こるか
ある推薦チームが、事業上は +1% 、すなわち +80 秒の改善なら採用価値があると考えたとする。しかし、利用可能なトラフィックでは、検出力 80% を満たす MDE が +200 秒だったとする。この設計で実験して p 値が 0.20 だった場合、結論は「+200 秒級の大きな改善は確認できなかった」に近い。価値がある +80 秒の改善まで否定したことにはならない。
このとき、次の二つは異なる主張である。
「この実験では勝ちを確認できなかった」。
「この施策には採用価値がない」。
後者を言うには、少なくとも実用下限 +80 秒を十分な精度で評価できるように実験を設計する必要がある。MDE を報告書に残す目的は、この二つを混同しないためである。
メトリクス選択は感度と妥当性の両方で行う
本文の収益額と購入有無の対比は、メトリクス設計の重要な原則を示している。収益額は購入額の大きなユーザーに強く左右され、分散が大きくなりやすい。一方、購入有無は 0/1 であるため、同じ人数でより狭い信頼区間を得られる場合がある。
Hulu の推薦でも、対応する例がある。
| 指標候補 | 長所 | 注意点 |
|---|---|---|
| 1 profile あたり総視聴秒数 | 視聴量という価値を直接反映しやすい。 | 分布の歪みと外れ値で分散が大きい。バックグラウンド再生等の定義も必要である。 |
| 25% 以上視聴したユニークシリーズ数 | unique_viewed_series
の定義を利用でき、弱いクリックより質が高い。 |
1 本の深い視聴と複数作品の浅い探索を同一方向に評価し得る。シリーズ単位なのでエピソード継続とは異なる。 |
| 推薦棚からの再生開始率 | 介入への近接性が高く、感度が高い可能性がある。 | 再生開始だけを最適化すると、釣り的な推薦や短時間離脱を増やす恐れがある。 |
| 一定割合以上の視聴率 | 暗黙的フィードバックとして再生開始より強い。 | 作品長、ジャンル、連続ドラマか映画かで解釈が変わる。 |
| 7 日後再訪率・継続視聴 | 長期価値に近い。 | 必要期間と標本数が増え、他施策・季節性の影響を受けやすい。 |
この表から分かるように、感度が高い近接指標だけを OEC にするのは危険である。推薦棚クリックが上がっても、総視聴時間、完走、継続、満足度が下がるなら価値はない。実務では、主要 OEC を一つまたは少数に固定し、因果連鎖を確認するための診断指標と、悪化を許容しないガードレール指標を分ける。
例えば、ホームの個人化ランキング変更では、次のような設計があり得る。
OEC: 対象 profile あたりの 7 日間 25% 以上視聴ユニークシリーズ数。
診断指標: 対象棚の表示率、棚からの作品詳細遷移率、棚起点の再生開始率、再生後 25% 到達率。
ガードレール: 総視聴秒数、再生エラー率、検索利用の急増、キッズ profile での年齢不適切露出、苦情や解約に関する指標。
ただし、複数の指標を見れば、偶然どれかが有意になる確率は上がる。主要 OEC と意思決定規則を事前に固定し、補助指標は診断として解釈するか、複数比較の扱いをあらかじめ決める必要がある。
実験デザインの四つの決定
本文の四つの問いは、統計計算の前提を決める問いでもある。順番に見ていく。
1. ランダム化単位は何か
推薦体験を個人に合わせる Hulu では、通常、profile_id
をランダム化単位にするのが自然である。content_viewing と
unique_viewed_series も profile 単位で記録され、GA4 の
user_id は仕様上 profile_id
が入るため、露出から視聴まで接続しやすい。
ただし、ランダム化単位と分析単位は、なぜそうするのかを明記する必要がある。例えば account 単位にランダム化し、profile 単位で分析すると、同一 account 内の複数 profile の相関がある。逆に profile 単位で異なる群を割り当てると、家族内で異なる体験をして比較・干渉する可能性がある。共有されるウォッチリストや視聴履歴、アカウント設定がどの単位かも確認対象である。
また、推薦モデル変更が「作品」側の露出を大きく動かす場合、同一作品への露出集中が他 profile の選択肢に影響するような干渉も理論上あり得る。一般的なユーザー単位 A/B テストは、ある profile の処置が別 profile の結果を変えないという仮定を置く。この仮定が強く破れる施策では、通常の二群比較だけでは因果解釈が難しくなる。
2. ターゲット母集団と分析対象をどう定義するか
「全 profile にランダム化する」ことと「分析で誰を分母にするか」は区別する。
原則として、主要分析は、割当後の行動でユーザーを選ばない Intent-to-Treat の形にする。例えば、ホーム推薦ランキングを変えるなら、実験対象として割り当てられた eligible profile を分母に含める。実験後に「棚を見た profile だけ」「クリックした profile だけ」を選ぶと、介入がその選択自体を変えるため、選択バイアスが入る。
一方、まったく露出し得ない profile を無制限に含めると効果が希釈される。適切な方法は、後から露出した人だけを選ぶことではなく、割当前に利用可能な情報で eligible 母集団を定義することである。例えば、施策が TV アプリのホーム画面にしか実装されないなら、実験開始前に「対象バージョンの TV アプリを利用可能な profile」をターゲットにする。キッズ向け棚でないなら、キッズ profile を事前に除くか、キッズ専用に別実験として設計する。
daily_personalize_viewing_kpi には
is_kids、is_owner、keizoku_flag
と profile 単位の
total_viewing_seconds、series_cnt、asset_cnt
がある。これらは集計・セグメント設計の候補になり得るが、実験開始後の値であれば主要分析のフィルタに使ってはならない。例えば「実験期間中に視聴した
profile
だけ」に絞ると、ランキング変更が視聴有無に与えた効果を自分で除外してしまう。
ワークド例:棚を見た profile だけに絞ると、結論が逆転し得る
各群に 1,000 profile を割り当て、OEC を「7 日間の 25% 以上視聴ユニークシリーズ数」とする。説明のため、棚を見なかった profile の OEC はすべて 0 と仮定する。
| 群 | 割当 profile 数 | 棚を見た profile 数 | 棚を見た profile の平均 OEC | 全割当 profile の平均 OEC |
|---|---|---|---|---|
| Control | 1,000 | 500 | 4.0 | |
| Treatment | 1,000 | 700 | 3.0 |
棚を見た profile だけを見ると、Treatment は 3.0 本、Control は 4.0 本であり、新ランキングが悪化したように見える。しかし、新ランキングが棚を見てもらえる profile を 500 人から 700 人に増やしたなら、割当 profile 全体での OEC は 本/profile で改善している。
ここで棚閲覧は介入後に生じた変数である。Treatment が「誰が棚を見るか」を変えたため、棚閲覧者だけを比較すると、二群で異なる人々を比べることになる。主要分析を割当済みの eligible profile 全体で行う Intent-to-Treat にする理由は、この選択バイアスを避けるためである。
3. 標本サイズはどの程度必要か
標本サイズは、少なくとも次を入力として決める。
主要メトリクスのベースライン平均と分散。過去の同じ曜日構成・同じ対象 profile・同じ集計窓から推定する。
実用的な最小効果、すなわち MDE。
有意水準 と検出力 。
群数と配分比。複数の treatment があれば各 treatment の必要人数を別に満たす。
想定される計測欠損、対象外化、ランプアップ、分析除外の扱い。
コントロール、介入 A、介入 B の三群を 34% / 33% / 33% に分ける教科書の例では、A 対 control、B 対 control の二つの比較をする。control は二つの比較で共有されるため、control を少し大きくする設計には合理性がある。ただし、二つの比較を同じ実験で主要結論として扱うなら、比較回数に応じた偽陽性の制御も必要になる。どちらか一方が p < 0.05 なら勝ち、という後付けのルールは偽陽性率を高める。
実験途中で毎日 p 値を見て、p < 0.05 になった日に止める行為も問題である。固定期間・固定標本数の通常の検定は、あらかじめ一度だけ判定する前提で 5% を保証する。途中判定を許すなら、逐次検定、alpha spending、ベイズ的監視など、繰り返し見ることを織り込んだ方法を採用する必要がある。
4. 実験期間をどう決めるか
期間は、必要 profile 数を集めるだけで決めてはならない。最低限、次を満たす必要がある。
必要な eligible profile 数が各群に入る。
曜日効果を一巡含める。Hulu の視聴は平日夜、週末、連休で強く変わり得るため、原則として丸 1 週間以上を含める。
介入への慣れ、プライマシー、ノベルティが落ち着くまでの時間を考慮する。
コンテンツ配信開始・配信終了、大型ライブイベント、祝日、キャンペーンなどの外的変化を記録し、結果の一般化可能性を確認する。
プライマシー効果とは、新しい UI や棚を初めて見たこと自体が行動を変える効果である。ノベルティ効果は、その新しさによる一時的な反応を指すことが多い。例えば、新しい「今夜のおすすめ」棚に興味を持って最初の数日だけタップが増えるかもしれない。しかし、その作品選定が本当に満足につながらなければ、数日後にはタップ率も継続視聴も下がる可能性がある。逆に、視聴履歴を学習して説明文を信頼するまで時間がかかる機能なら、初期値だけで失敗と結論するのは早い。
日次の効果を可視化することは、途中で有意になったから止めるためではなく、効果の安定性、計測異常、曜日差、コンテンツイベントとの関係を診断するために行う。最終判定の集計窓と停止規則は事前に固定する。
ワークド例:必要人数が 4 日で集まっても、7 日待つ理由
各群に必要な 39,200 profile があり、eligible profile が 1 日あたり合計 20,000 人、Control / Treatment に 50% ずつ入るとする。単純計算では、各群に 1 日 10,000 profile ずつ入るため、必要人数を集める日数は次である。
人数だけなら 4 日目に終了できる。しかし、月曜から木曜だけの結果には金曜夜や週末の視聴行動が入らない。例えば、週末に家族でアニメや映画を視聴する profile が多いなら、TV デバイス比率、視聴時間、作品選択が平日と異なる。4 日で止めると、その変更が「平日には有効だが週末は悪化する」のかを見逃す。
そのため、実験開始日を月曜にそろえ、少なくとも日曜までの 7 日間を実施する設計には意味がある。7 日で各群 70,000 profile になれば、必要人数を満たすだけでなく、曜日一巡を含む推定になる。ただし、同じ profile の再訪を新規 profile 数として二重に数えないこと、週末の大型作品配信などの外的要因を記録することは別途必要である。
Hulu の推薦実験に落とす具体例
ここでは、ホーム画面の「あなたへのおすすめ」棚のランキングを、既存モデルから新しい候補生成・ランキングモデルへ置き換える例で考える。目的は、クリックだけではなく、作品を実際に視聴する機会を増やすことである。
事前登録に近い形で決める内容
| 項目 | 設計例 | 理由 |
|---|---|---|
| ランダム化単位 | profile_id |
個人化推薦の処置と主要視聴ログの単位をそろえる。 |
| 対象母集団 | 実験開始時点で対象アプリ版を利用可能な、非キッズのアクティブ profile | 施策が露出し得る集団を事前情報で定義する。 |
| コントロール | 現行のランキング | 比較基準を固定する。 |
| 介入 | 新ランキング。ただし UI、棚位置、カード数は固定する | モデル効果と UI 効果を混ぜない。 |
| 主要 OEC | 割当後 7 日間の 25% 以上視聴ユニークシリーズ数 / eligible profile | 露出後に選別せず、視聴品質を最低限反映する。 |
| 診断指標 | 棚表示率、棚起点の詳細遷移、再生開始、25% 到達 | 効果がファネルのどこで生じたかを調べる。 |
| ガードレール | 総視聴秒数、再生エラー率、検索経由比率、コンテンツ多様性 | 短期の選択増が体験全体を損ねていないか確認する。 |
| 最小実用効果 | OEC の相対 +1% 以上、かつガードレールに許容不能な悪化がないこと | 採用する価値の基準を統計と独立に定める。 |
| 検定 | 両側 5%、80% 以上の検出力 | 改善と悪化の両方を検出対象にする。 |
| 期間 | 必要人数を満たし、月曜から日曜までを含む最低 1 週間。新 UI なら 2 週間以上も検討 | 曜日と初期効果を評価する。 |
この設計で、主要 OEC の相対差が +1.4%、95% 信頼区間が 、p 値が 0.01 だったとする。ゼロを含まないため統計的には改善である。さらに区間の下限が実用下限 +1% を下回るため、「真の改善が少なくとも 1% である」とまでは 95% 信頼区間だけから言えない。この場合、即時の全面展開より、ガードレールと運用コストを確認して段階展開する、または精度を上げる追加実験をする、といった判断があり得る。
反対に、相対差が +0.4%、95% 信頼区間が 、p 値が 0.12 だったとする。これは「効果がない」とは言えないが、あらかじめ定めた +1% の改善を支持する証拠もない。もし実験が +1% に対して十分な検出力を持っていたなら、少なくとも「採用に値するほどの改善は得られなかった」と判断できる。これが、p 値だけでなく設計時の MDE と信頼区間を見る理由である。
暗黙的フィードバックで特に注意する点
暗黙的フィードバックは、ユーザーが「好き」と明示した結果ではない。再生開始は、真の興味のほか、自動再生、誤タップ、作品情報不足、続きを見たためなどの影響を受ける。25% 視聴も、作品長、エピソードの途中再開、家族共有、デバイスの状態に影響され得る。したがって、メトリクスを一つの真実と扱わず、何をどこまで代理しているかを明記する必要がある。
例えば unique_viewed_series の 25%
到達は、短いプレビュー視聴より強いシグナルである。しかし、シリーズ単位のユニーク数を増やす新モデルが、作品を広く試させる一方で、一本あたりの深い視聴を減らす可能性もある。この場合、ユニークシリーズ数だけを勝利条件にすると探索量の増加を過大評価する。content_viewing.watched_seconds、連続エピソード数、翌週の再訪などをガードレールまたは補助的な長期指標として組み合わせる理由はここにある。
実験結果を読むときの実務的な順序
実験終了後の分析は、p 値を見ることから始めない。次の順序が安全である。
割当と計測の健全性を確認する。群サイズ、対象条件、イベント送信率、主要な割当前共変量のバランスを確認する。想定割合から群サイズが大きく乖離する Sample Ratio Mismatch は、統計的結論より先に調査すべき異常である。
事前定義した主要分析対象と集計窓で、群ごとの人数、平均、絶対差、相対差、信頼区間、p 値を出す。
信頼区間がゼロをまたぐかだけでなく、実用下限をまたぐかを確認する。
ガードレールと診断指標を確認する。主要 OEC の改善が、再生エラー、総視聴、コンテンツ多様性などの重大な悪化と引き換えでないかを見る。
事前に重要と定めたセグメントを確認する。プラットフォーム、デバイス、キッズ/非キッズ、既存視聴量などで効果の方向が整合するかを見る。ただし、実験後に多数の切り口を掘って偶然有意な群だけを採用しない。
日次推移とコンテンツ・カレンダーを確認する。特定日の配信開始、週末、障害、キャンペーンだけで結果が作られていないかを見る。
セグメント分析では、全体で十分な検出力があっても、各セグメントでは人数が不足しやすい。例えば全 profile で 80% の検出力があっても、TV アプリだけ、ある地域だけ、新規 profile だけでは大幅に低下する。全体とセグメントのどちらを主要な意思決定対象にするかは、実験設計時に決める必要がある。
よくある誤解と修正
「p 値が 0.05 以上なので、差はゼロである」
誤りである。p 値が大きいのは、ゼロとの差を十分な精度で検出できなかったことを意味する。信頼区間が広ければ、実用上大きな改善も悪化も残っている。差が十分小さいことを示したいなら、等価性・非劣性の枠組みを使う。
「p 値が小さいので、出稿すべきである」
誤りである。統計的有意差は、効果の事業価値、実装コスト、長期影響、ガードレール、安全性を判断しない。巨大トラフィックでは、価値のない微小効果も有意になる。
「実験を長く回せば、必ず精度が上がる」
一般には標本数が増えて精度は上がるが、効率は一定ではない。新規 profile の増加は鈍化し、累積メトリクスの分散は大きくなり、曜日・季節性・ノベルティ・他施策も入り込む。必要人数と代表的な周期を満たした上で、長期効果を測る目的があるときに期間を延ばす。
「クリック率が有意に上がったので、推薦品質が上がった」
必ずしも言えない。より目立つカード、刺激的なタイトル、上位棚への移動だけでもクリックは上がる。推薦の価値を主張するには、再生開始後の視聴、総視聴、継続、満足度、ガードレールまでの因果連鎖を確認する。
「棚を見た profile だけで比較すれば、効果が見えやすい」
主要な因果推定としては危険である。棚を見ること自体がランキングや UI によって変わり得るため、介入後の変数で分母を選んでいる。事前に定義した eligible profile 全体での Intent-to-Treat を主分析にし、露出者分析は診断的な補助分析として慎重に扱う。
「複数の treatment を試して、一つでも有意なら成功である」
そのままでは偽陽性が増える。複数の比較、複数の主要指標、複数の途中確認をするなら、比較ファミリーと補正・判定規則を事前に決める。介入ごとに独立に十分な検出力を持たせることも必要である。
この節の要点
仮説検定は、観測差が偶然の割当ばらつきで説明しにくいかを評価する道具である。しかし、正しい結論は p 値一つからは出ない。
標準誤差は平均との差の不確実性であり、標本数、メトリクスの分散、割当単位に依存する。
両側 5% 検定では、p 値が 0.05 未満であることと、95% 信頼区間がゼロを含まないことは等価である。信頼区間は効果量と精度も示すため、必ず併記する。
統計的有意性は偶然との整合性を示すだけであり、実用的有意性、すなわち採用に値する大きさはプロダクトと事業が定める。
検出力は、あらかじめ決めた意味のある効果を見逃さない確率である。MDE、標本数、有意水準、検出力は、結果を見る前に一貫して決める。
Hulu の推薦実験では、
profile_idを中心に、露出・選択・視聴を接続しつつ、暗黙的フィードバックの限界、曜日、作品供給、ノベルティ、セグメント、複数比較を設計に含める。
最終的に目指すべきなのは、「p < 0.05 だった」という報告ではない。どの profile に、どの変更を、どの期間見せた結果、どの程度の効果が、どの不確実性を伴って観測され、その大きさと副作用が採用判断に見合うかを説明できる状態である。