ch2-1 問題設定と仮説の作り方:変更案を実験可能な問いに変換する
この節の中心メッセージは、A/B テストは「何かを変えて、良くなったかを見る」だけの作業ではなく、まず 問題設定 と 仮説 を明確にする必要がある、ということである。つまり、実験を始める前に、次の問いに答えられる状態にしておく必要がある。
何を変えるのか。
その変更は、ユーザー行動のどの部分に影響すると考えているのか。
その影響は、どのメトリクスに現れるはずなのか。
そのメトリクスの分母には、どのユーザーを含めるべきなのか。
期待している変化は改善なのか、悪化なのか、それともリスク確認なのか。
教科書の例では、架空のオンラインコマースサイトが、購入確認ページにクーポンコード入力欄を追加する。これは一見すると小さな UI 変更である。しかし、この小さな UI 変更は、売上や購入完了率に影響し得る。なぜなら、購入直前のユーザーに「どこかにクーポンがあるのではないか」と思わせ、検索に離脱させたり、クーポンが見つからないことで損をした気分にさせたり、最終的に購入完了を遅らせたり中止させたりする可能性があるからである。
Hulu の動画推薦でも、同じ構造が頻繁に現れる。例えば、推薦棚に「あなたにおすすめ」ではなく「今週あなたに人気」と表示する、公開終了が近い作品を上位に出す、TVOD 作品を SVOD 作品の間に混ぜる、作品カードにジャンルや出演者情報を追加する、といった変更は、一見すると小さく見える。しかし、暗黙的フィードバック、つまりクリック、再生開始、25% 以上視聴、完走、翌日再訪問などに影響し得る。したがって、推薦 ML の実験でも、単に「新モデルを出す」ではなく、「この変更は、誰の、どの行動を、どの方向に変えるはずか」を明確にすることが重要である。
第2章の位置づけ
第 1 章では、直感や社内の強い意見だけではなく、実際のユーザーから得られるデータによって意思決定する重要性が説明された。第 2 章では、その考え方を一歩進めて、実験をどのように設計し、実行し、分析するかの基本的な流れを扱う。
ここで重要なのは、実験の技術的な実装より前に、問いの立て方があるという点である。A/B テストの失敗は、統計手法の間違いだけで起こるわけではない。むしろ実務では、次のような問題設定の曖昧さが、解釈不能な実験を生みやすい。
変更内容は決まっているが、何を改善したいのかが曖昧である。
メトリクスは決まっているが、そのメトリクスが仮説と対応していない。
分母に含めるユーザーが広すぎて、効果が希釈されている。
分母に含めるユーザーが狭すぎて、介入後に選ばれたユーザーだけを見てしまっている。
「勝ったら出す」ことだけが目的になり、なぜ勝ったのか、なぜ負けたのかを学習できない。
したがって、この節は、A/B テストの実装以前にある「実験として成立する問いの作り方」を説明していると読むとよい。
クーポンコード入力欄の例で何を調べているのか
教科書の例では、マーケティング部門がプロモーションメールでクーポンコードを配布し、売上を伸ばしたいと考えている。しかし、会社はまだクーポンを提供したことがない。そのため、クーポンという仕組みを導入することは、単なる UI 変更ではなく、ビジネスモデルの変更にもなり得る。
ここで問題になるのは、クーポンコード入力欄そのものが、ユーザーの購入行動を悪化させる可能性である。クーポン欄を見ると、ユーザーは次のように考えるかもしれない。
「クーポンを持っていない自分は損をしているのではないか」
「検索すればクーポンコードが見つかるかもしれない」
「今すぐ買わず、あとでクーポンを探してから買おう」
「クーポンなしで買うのはもったいない」
その結果、購入確認ページまで来ていたにもかかわらず、購入完了前に離脱する可能性がある。つまり、クーポン入力欄は、ユーザーに値引きの機会を示す一方で、購入完了を妨げる摩擦にもなり得る。
この例の面白い点は、実際のクーポンシステムをまだ実装していないことである。入力欄だけを追加し、ユーザーが何を入力しても「無効なクーポンコード」と表示する。これは、クーポン機能全体の価値を測る実験ではなく、 クーポン入力欄を見せること自体の悪影響を測る実験 である。
このような実験は、プロダクト開発では非常に重要である。なぜなら、大きな機能を作り込む前に、その機能の一部や入口だけを見せて、ユーザー行動がどう変わるかを確認できるからである。もちろん、ユーザーを欺く設計には倫理的・ブランド上の注意が必要である。しかし、実装コストの大きい施策に対して、最初に小さな検証を行うという考え方自体は重要である。
Hulu の推薦に置き換えると、例えば「AI が選んだ今夜の一本」という新しい推薦体験を考えるとする。いきなり大規模な生成 AI や会話 UI を実装しなくても、まずは既存推薦ロジックで選んだ作品にそのラベルを付けたとき、クリック率や再生開始率がどう変わるかを確認できる。この場合に測っているのは、真の意味での AI 推薦品質ではなく、 その見せ方や期待形成がユーザー行動に与える影響 である。
ファネルとして考える理由
教科書は、オンラインショッピングの流れをファネルとして表現している。
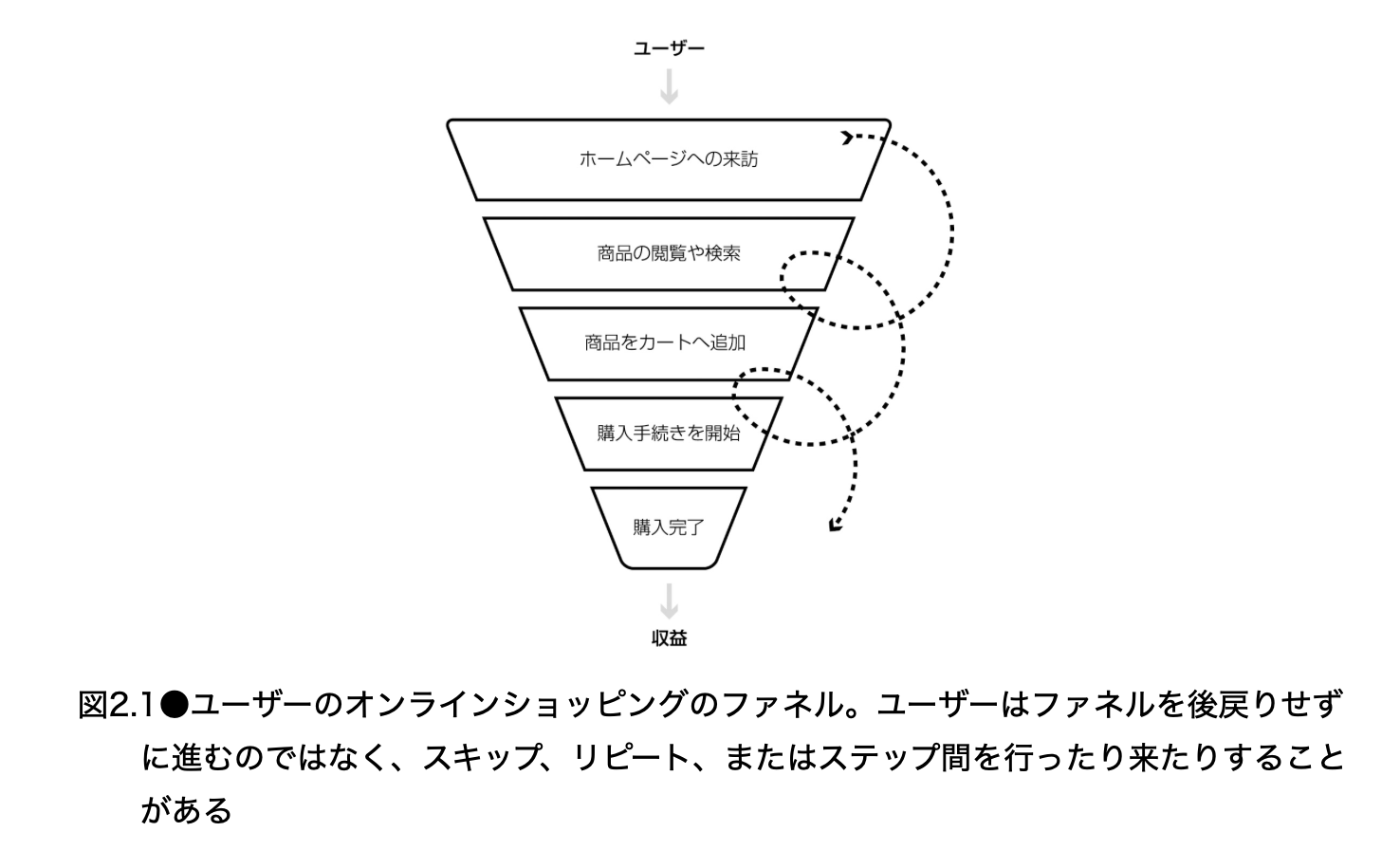
ファネルとは、ユーザーが最終的なゴールに到達するまでの代表的な段階を並べたモデルである。この例では、最終的なゴールは購入完了であり、そこに至るまでに、ホームページ訪問、商品閲覧、カート追加、購入手続き開始といった段階がある。
ただし、教科書が注意しているように、ファネルは現実のユーザー行動を完全に表すものではない。ユーザーは必ずしも一方向に進むわけではない。商品を見て戻ることもある。検索し直すこともある。カートに入れた商品を削除することもある。別の商品を追加することもある。したがって、ファネルは現実そのものではなく、実験設計のための単純化である。
それでも、ファネルは有用である。なぜなら、ある変更がファネルのどこに置かれるかを考えることで、影響を受けるユーザーと、影響を受けないユーザーを区別できるからである。
今回のクーポン入力欄は、購入確認ページに置かれる。したがって、ホームページだけを見て離脱したユーザーや、商品を閲覧しただけのユーザーは、この変更を見ていない。カートに商品を入れたが購入手続きを開始しなかったユーザーも、おそらくこの変更を見ていない。変更の影響を受ける可能性があるのは、購入手続きを開始し、購入確認ページに到達する可能性があるユーザーである。
この考え方は、Hulu の推薦実験でも非常に重要である。Hulu の視聴体験を単純化すると、例えば次のようなファネルとして表せる。
アプリまたは Web を開く。
ホーム画面や検索画面で作品候補を見る。
推薦棚または検索結果で作品カードを見る。
作品詳細ページを開く。
再生を開始する。
一定割合以上を視聴する。
エピソードやシリーズを継続視聴する。
後日再訪問する。
Hulu の unique_viewed_series は、profile_id
ごとに、動画コンテンツ長の 25%
以上を視聴したシリーズを記録するテーブルである。これは「ただ表示された」「クリックした」よりも強い暗黙的フィードバックである。したがって、推薦実験の
OEC として「1 profile あたり 25%
以上視聴したユニークシリーズ数」を置くことは自然である。ただし、そのメトリクスを使う場合でも、どの
profile を分母にするかは慎重に決める必要がある。
図2.2の2つの介入の意味
教科書では、クーポン入力欄の見せ方として 2 つの UI 実装を試している。
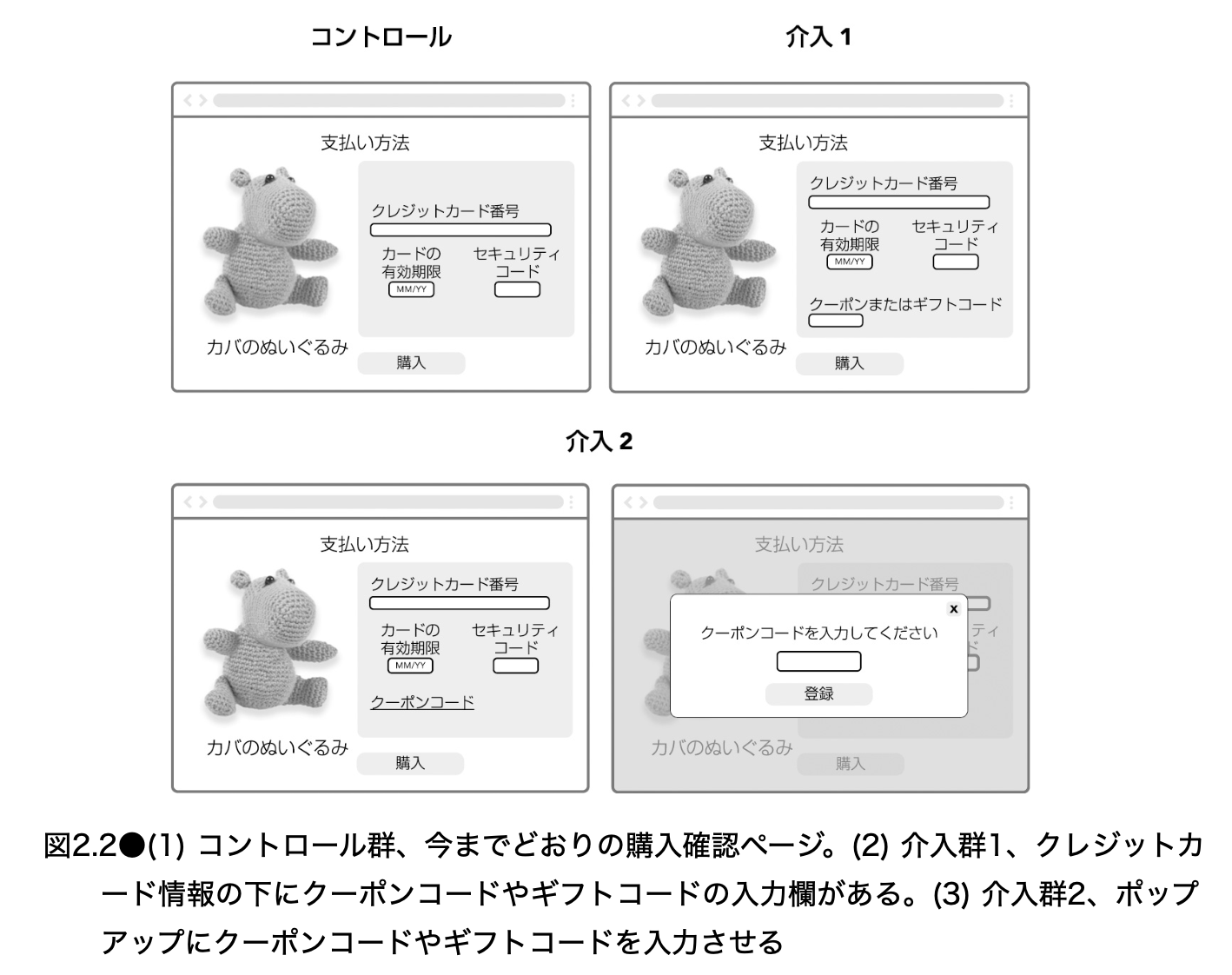
ここで区別すべきなのは、 アイデア と 実装 である。
アイデアは「購入確認ページにクーポンコード入力の機会を追加する」ことである。一方、実装は「その入力欄を常に表示するのか」「リンクとして表示し、クリック後にポップアップで入力させるのか」といった具体的な UI である。
この区別は重要である。なぜなら、実験結果が悪かったときに、失敗したのがアイデアなのか、実装なのかを考える必要があるからである。
例えば、介入 1 が大きく悪化し、介入 2 はほとんど悪化しなかったとする。この場合、「クーポンコードという概念そのものが悪い」とは言い切れない。常に入力欄を見せる UI が、ユーザーに強くクーポン探索を促してしまった可能性がある。一方、リンク表示にすれば、クーポンを持っているユーザーだけが開くため、悪影響が小さくなるかもしれない。
逆に、介入 1 も介入 2 も悪化したなら、クーポン入力の存在自体が購入体験を阻害している可能性が高まる。このように、複数の実装を同時に試すことで、アイデアの良し悪しと実装の良し悪しをある程度切り分けられる。
Hulu の推薦でも同じである。例えば「公開終了が近い作品を推薦する」というアイデアがあるとしても、実装はいくつも考えられる。
通常の推薦ランキングの中で少しだけブーストする。
「まもなく配信終了」棚を新設する。
作品カードに「あと 7 日」とラベルを付ける。
視聴済みシリーズの続編や関連作だけに限定して出す。
キッズプロフィールでは出さない、または弱める。
これらは同じアイデアに見えるが、ユーザー体験としてはかなり異なる。ランキング内で自然に上げるだけなら視聴開始が増えるかもしれない。一方、強いラベルを出すと、焦りを生むことで視聴を促す可能性もあるが、圧迫感を与えて体験を悪化させる可能性もある。したがって、推薦 ML の実験では、モデル変更だけでなく、提示方法も介入の一部として扱う必要がある。
最初の仮説はなぜ不十分なのか
教科書では、最初の仮説として「購入確認ページにクーポンコードのフィールドを追加すると、収益が低下する」という形を置いている。これは方向性としては分かりやすい。しかし、実験仮説としてはまだ粗い。
なぜなら、「収益が低下する」と言っても、どの収益を、どのユーザー集合で、どの期間で、どの単位に正規化して見るのかが明確でないからである。
例えば、総収益を見るとする。Control 群に 100,000 人、Treatment 群に 99,000 人が割り当てられたとき、Treatment 群の総収益が低く見えるのは当然かもしれない。実験割り当てが同じ確率でも、実際のユーザー数は偶然に少しずれる。したがって、総収益をそのまま比較すると、ユーザー数の違いと介入効果が混ざってしまう。
この問題を避けるため、教科書は「ユーザー当たりの収益」を OEC として使うことを推奨している。OEC とは Overall Evaluation Criterion の略であり、実験の成功を判断するための主要指標である。ここでは、単純化すれば「この実験では最終的に何を良し悪しの基準にするか」である。
ユーザー当たりの収益は、次のように書ける。
このように正規化すれば、Control 群と Treatment 群のユーザー数が少し違っても比較しやすくなる。
ただし、これだけではまだ不十分である。次に決めるべきなのは、分母のユーザーを誰にするかである。
分母の選び方が実験の解釈を決める
教科書は、ユーザー当たり収益の分母として 3 つの候補を挙げている。
サイトを訪問したすべてのユーザー。
購入プロセスを完了したユーザーのみ。
購入プロセスを開始したユーザーのみ。
この 3 つは、どれも一見もっともらしい。しかし、実験の問いに対して適切かどうかは異なる。
すべての訪問ユーザーを分母にする場合
サイトを訪問したすべてのユーザーを分母にすることは、原理的には有効である。ランダム化されたユーザー全体を比較するため、介入後の行動でユーザーを選別する問題が少ないからである。
しかし、この分母はノイズが大きい。なぜなら、購入確認ページまで到達しないユーザーが大量に含まれるからである。今回の変更は購入確認ページに置かれている。したがって、そこまで到達しなかったユーザーは、そもそも変更を見ていない。そのようなユーザーを大量に分母に含めると、変更の効果が薄まる。
例えば、サイト訪問者が 100,000 人いて、そのうち購入手続きを開始するユーザーが 10,000 人だけだとする。クーポン入力欄は、この 10,000 人にしか影響しない。もし購入手続きを開始したユーザー内では収益が 5% 悪化しても、全訪問者で見ると見かけの悪化はかなり小さくなる。
単純化して、影響を受けるユーザー割合を 、影響を受けるユーザー内の相対効果を とすると、全体で観測される相対効果は次のように近似できる。
ここで、 、 なら、全体効果は次のようになる。
影響を受けたユーザー内では 5% の悪化なのに、全訪問者で見ると 0.5% の悪化に見える。これは、効果が存在しないという意味ではない。分母が広すぎるために、効果が希釈されているのである。
Hulu の推薦でも同じことが起きる。例えば、ホーム画面の 5 番目の推薦棚だけを変更する実験で、全 profile を分母にして「1 profile あたり 25% 以上視聴ユニークシリーズ数」を見るとする。しかし、実験期間中にホーム画面を開かなかった profile、5 番目の棚までスクロールしなかった profile、そもそも推薦対象外のキッズ制約がある profile などは、この変更の影響をほとんど受けない。これらを全て含めると、実際に変更を見た profile 内では意味のある効果があっても、全体では小さく見える。
購入完了ユーザーだけを分母にする場合
購入プロセスを完了したユーザーだけを分母にするのは、一見すると自然に見える。収益は購入者から発生するため、購入者あたり収益を見ればよさそうに思えるからである。
しかし、これは今回の仮説には適切でない。理由は、購入完了そのものが介入の影響を受ける可能性があるからである。
今回の懸念は、クーポン入力欄によって購入完了率が下がることである。ところが、購入完了したユーザーだけを分母にすると、購入をやめたユーザーが分析から消えてしまう。これは、介入後の結果によってユーザーを選別していることになる。
極端な例を考える。Control 群では 100 人が購入手続きを開始し、50 人が購入完了し、購入者 1 人あたり平均 2,000 円を払ったとする。総収益は 100,000 円である。
Treatment 群では、クーポン欄のせいで購入完了者が 40 人に減ったが、購入した人の平均購入額は 2,100 円だったとする。総収益は 84,000 円である。
購入者あたり収益だけを見ると、Treatment は次のように良く見える。
しかし、購入手続き開始者あたり収益で見ると、Control は次の通りである。
Treatment は次の通りである。
つまり、購入手続きを開始したユーザーあたりでは 16% の悪化である。
この例から分かるように、購入完了者だけを見ると、購入をやめた人の影響を見落とす。今回の仮説が「購入完了を妨げるかもしれない」というものなら、購入完了者だけを分母にしてはいけない。
Hulu の推薦でも、これに似た落とし穴がある。例えば、新しい推薦モデルの評価で「再生開始した profile の中での 25% 以上視聴率」だけを見るとする。しかし、新モデルがそもそも再生開始数を減らしている可能性がある。再生開始した profile だけに絞ると、再生しなかった profile が消えるため、モデルがユーザーを迷わせた、あるいはクリックしたくなる作品を出せなかった、という悪影響を見落とす。
購入プロセスを開始したユーザーを分母にする場合
教科書が最も適切だとしているのは、購入プロセスを開始したユーザーを分母にする方法である。理由は、今回の変更が購入確認ページ付近に置かれており、購入プロセスを開始したユーザーがその影響を受ける可能性を持つからである。
この分母には、変更の影響を受ける可能性があるユーザーが含まれる。一方で、そもそも購入プロセスに入っていないユーザーは除外される。したがって、分母が広すぎて効果が希釈される問題を減らしつつ、購入完了者だけを見ることによる選択バイアスも避けやすい。
ここで重要なのは、分母を「介入前、または介入に影響されにくい段階」で定義することである。購入プロセスを開始したかどうかは、クーポン入力欄を見る前の行動である。そのため、分母として比較的安全である。一方、購入完了したかどうかは、クーポン入力欄の影響を受けた後の結果であるため、分母にすると危険である。
この考え方は、推薦実験では特に重要である。推薦はユーザーの行動を変えるため、介入後の行動で分母を切ると、評価が歪みやすい。
例えば、Hulu で「ホーム画面の第 1 推薦棚のランキングを変更する」実験を考える。この場合、分母として自然なのは、実験期間中にホーム画面を表示した profile、または第 1 推薦棚が表示される画面に到達した profile である。逆に、「推薦棚から作品詳細を開いた profile だけ」を分母にすると危険である。なぜなら、作品詳細を開くかどうか自体が、新しいランキングの影響を受けるからである。
洗練された仮説とは何か
以上を踏まえると、教科書では仮説を次のように洗練させている。
「購入確認ページにクーポンコード入力欄を追加すると、購入プロセスを開始するユーザーの 1 ユーザー当たりの収益が低下する」
この仮説は、最初の「収益が低下する」よりもかなり良い。理由は、次の 3 点が明確になっているからである。
介入: 購入確認ページにクーポンコード入力欄を追加する。
対象ユーザー: 購入プロセスを開始するユーザー。
OEC: 1 ユーザー当たりの収益。
さらに、期待される方向も「低下する」と明確である。これは、実験後の解釈に役立つ。例えば、実際に低下すれば、懸念が支持されたと考えられる。低下しなければ、クーポン欄による悪影響は少なくとも検出できなかったと考えられる。逆に上昇すれば、クーポン欄が安心感や購入意欲を高めている可能性など、別の仮説を考える必要がある。
Hulu の推薦で同じ形式にすると、例えば次のような仮説になる。
「ホーム画面の第 1 推薦棚で、 avg_fingerprint
による内容類似候補をランキング特徴量に追加すると、ホーム画面を表示した
profile の 14 日間における 1 profile あたり 25%
以上視聴ユニークシリーズ数が増加する」
この仮説には、介入、対象、期間、OEC、方向が含まれている。
介入:
avg_fingerprintによる内容類似候補をランキング特徴量に追加する。対象: ホーム画面を表示した profile。
期間: 14 日間。
OEC: 1 profile あたり 25% 以上視聴ユニークシリーズ数。
期待方向: 増加する。
このように書くと、実験前に議論すべき点が明確になる。例えば、14 日間でよいのか、7 日間では短すぎるのか、25% 以上視聴だけでなく再生開始も見るべきか、TVOD 収益や継続率 proxy をガードレールにすべきか、といった議論ができる。
Hulu 推薦における分母選択の具体例
Hulu の推薦実験では、分母選択が特に難しい。なぜなら、推薦は全ユーザーに均一に効くわけではなく、表示面、デバイス、プロフィール種別、作品在庫、既視聴履歴、サービス種別、公開期間などに強く依存するからである。
例えば、 item_information_table には、
service_type として SVOD と TVOD があり、
publish_start_at や publish_end_at
によって作品の公開期間が管理されている。また、 avg_mood_tag
や avg_fingerprint のような外部 AI
による作品特徴量も存在するが、全作品に付与されているとは限らない。このような条件があるため、ある推薦変更が全
profile に同じように作用するとは限らない。
具体例として、「公開終了が近い SVOD 作品をホーム推薦で少し上位に出す」実験を考える。このとき、OEC を「1 profile あたり 25% 以上視聴ユニークシリーズ数」とする場合でも、分母候補はいくつかある。
全 profile。
実験期間中に Hulu を起動した profile。
ホーム画面を表示した profile。
公開終了が近い SVOD 作品を推薦候補に持つ profile。
公開終了が近い SVOD 作品が実際に表示された profile。
全 profile を分母にすると、変更の影響を受けない profile が大量に含まれるため、効果が希釈される。実験期間中に Hulu を起動した profile でも、ホーム画面や対象棚を見なかった profile が含まれる。ホーム画面を表示した profile は、変更の影響可能性に近づくため、より良い分母かもしれない。
一方で、「公開終了が近い SVOD 作品が実際に表示された profile」を分母にする場合は注意が必要である。表示されたかどうかは、新しいランキングの影響を受ける可能性がある。Treatment ではブーストによって表示され、Control では表示されなかった profile がいるなら、表示者だけに絞ると群間比較が歪む。
したがって、実験前に定義するなら、「実験開始時点またはリクエスト時点で、公開終了が近い SVOD 作品を候補集合に持っていた profile」や「ホーム画面の対象推薦リクエストが発生した profile」のように、介入によって変わりにくい条件で分母を定義する方が望ましい。
暗黙的フィードバックでは何を OEC にするべきか
Hulu では、明示的な星評価よりも、視聴の有無や視聴量といった暗黙的フィードバックが主である。そのため、推薦実験の OEC は、ユーザーが本当に価値を感じたかを代理する行動ログから作る必要がある。
候補としては、次のようなメトリクスが考えられる。
1 profile あたり再生開始数。
1 profile あたり 25% 以上視聴ユニークシリーズ数。
1 profile あたり総視聴時間。
1 profile あたり完走エピソード数。
翌日または翌週の再訪問率。
TVOD 作品の購入またはレンタル収益。
SVOD と TVOD を合わせた長期的な価値 proxy。
ただし、どれを OEC にするかは、施策の仮説によって変わる。例えば、クリックしやすいサムネイルを出す施策なら、再生開始数は敏感に反応するかもしれない。しかし、クリックだけ増えてすぐ離脱するなら、ユーザー価値は高まっていない。その場合、25% 以上視聴や完走率を併せて見る必要がある。
一方、長尺映画の推薦を増やす施策では、再生開始数は減るかもしれないが、総視聴時間や満足度 proxy は上がるかもしれない。短尺エピソードと長尺映画では、同じ「1 再生開始」の意味が違うため、OEC の選び方には注意が必要である。
unique_viewed_series は、コンテンツ長の 25%
以上を視聴したシリーズを記録するため、単なるクリックや数秒再生よりも強いシグナルである。ただし、シリーズ単位でユニークに数えるため、同じシリーズを何話も見た深いエンゲージメントは直接は反映されにくい。したがって、OEC
として使う場合は、「新しいシリーズとの出会い」を重視する実験には向いているが、「同一シリーズの継続視聴」を重視する実験では補助メトリクスが必要になる。
良い仮説のテンプレート
実務で使いやすい形にすると、良い実験仮説は次のテンプレートで書ける。
「対象面において、対象ユーザーに対して、介入を行うと、理由により、期間内の OEC が方向に変化する」
Hulu 推薦向けに、もう少し具体化すると次のようになる。
「ホーム画面の第 1 推薦棚において、ホーム画面を表示した profile
に対して、既視聴シリーズの avg_fingerprint に近い未視聴
SVOD
シリーズをランキングでブーストすると、ユーザーの現在の嗜好に近い作品が見つかりやすくなるため、14
日間の 1 profile あたり 25% 以上視聴ユニークシリーズ数が増加する」
この仮説は長いが、実験設計には向いている。なぜなら、次の要素が明確だからである。
どの面を変えるか: ホーム画面の第 1 推薦棚。
誰を対象にするか: ホーム画面を表示した profile。
何を変えるか: 既視聴シリーズの
avg_fingerprintに近い未視聴 SVOD シリーズをブーストする。なぜ効くと思うか: 現在の嗜好に近い作品が見つかりやすくなるため。
何で測るか: 14 日間の 1 profile あたり 25% 以上視聴ユニークシリーズ数。
方向は何か: 増加する。
この「なぜ効くと思うか」の部分も重要である。なぜなら、実験結果が予想と違ったときに、どの前提が間違っていたのかを考えられるからである。例えば、結果が悪化したなら、内容類似が強すぎて既視聴作品と似たものばかりになり、新鮮さが失われたのかもしれない。あるいは、
avg_fingerprint
が全作品に付与されていないため、候補の偏りが発生したのかもしれない。あるいは、短期的な
25% 視聴は増えたが、長期的な再訪問には効いていないのかもしれない。
悪い仮説の例
逆に、次のような仮説は実験設計として弱い。
「新しい推薦モデルは良いはずである」
「ユーザー体験を改善する」
「視聴を増やす」
「パーソナライズを強化する」
「精度が高いモデルなので KPI も上がる」
これらは方向性としては分かるが、実験仮説としては曖昧である。何を変えるのか、誰に効くのか、何を測るのか、いつまで見るのかが分からない。
例えば、「パーソナライズを強化する」と言っても、候補生成を変えるのか、ランキング特徴量を変えるのか、棚の順序を変えるのか、サムネイルを変えるのかで意味が違う。また、クリック率を上げたいのか、25% 以上視聴を上げたいのか、継続率を上げたいのかでも実験設計が変わる。
推薦 ML では、オフライン指標が良いモデルほどオンラインでも良いとは限らない。例えば、過去視聴に似た作品を高精度に当てるモデルは、短期的なクリック率を上げるかもしれない。しかし、似た作品ばかりを出すことで発見性を下げ、長期的な満足度を悪化させる可能性もある。したがって、「精度が高いから良い」ではなく、「どのユーザー行動をどう変えるはずか」まで落とす必要がある。
OEC とガードレールを分ける
この節では主に OEC の話が出てくるが、実務では OEC だけでは不十分である。特に Hulu の推薦では、短期的な視聴増加と、長期的な体験品質や事業上の制約が衝突することがある。
例えば、OEC を「1 profile あたり 25% 以上視聴ユニークシリーズ数」とする。新しい推薦モデルがこの OEC を上げたとしても、次のような悪影響があるかもしれない。
TVOD 作品を過度に下げ、TVOD 収益が悪化する。
特定ジャンルに偏り、カタログ消費の多様性が下がる。
キッズプロフィールに不適切な作品が混ざるリスクが上がる。
公開終了作品を強く出しすぎて、ユーザーに急かされる感覚を与える。
再生開始は増えるが、短時間離脱も増える。
レイテンシが悪化し、ホーム画面表示が遅くなる。
このような悪影響を検知するために、OEC とは別にガードレールメトリクスを設定する。OEC は「この実験で勝ちたい主要指標」であり、ガードレールは「これを壊してまで勝ってはいけない指標」である。
例えば、公開終了作品ブーストの実験なら、OEC は「1 profile あたり 25% 以上視聴ユニークシリーズ数」としつつ、ガードレールとして「短時間離脱率」「ホーム画面レイテンシ」「TVOD 収益」「キッズプロフィールでの不適切表示率」「作品多様性」などを見ることが考えられる。
問題設定から分析までの流れ
この節を実務フローとして整理すると、次の順番になる。
- まず、プロダクト上の問題または機会を言語化する。
例えば、Hulu で「ユーザーが観たい作品を見つけるまでに時間がかかっている」「新規配信作品が十分に発見されていない」「シリーズ完走後の次作品への遷移が弱い」といった問題を置く。
- 次に、ユーザー行動のどの地点に介入するかを決める。
ホーム画面なのか、検索結果なのか、作品詳細ページなのか、再生終了後画面なのかで、影響を受けるユーザーもメトリクスも変わる。
- その介入が効く理由を仮説として書く。
「内容類似作品を増やせば、既視聴作品の嗜好に近い未視聴作品が見つかりやすくなる」「公開終了作品を上げれば、見逃し回避ニーズを満たせる」などである。
- OEC を決める。
クリック率、再生開始数、25% 以上視聴ユニークシリーズ数、総視聴時間、再訪問率などから、仮説に最も対応するものを選ぶ。
- 分母を決める。
全 profile なのか、ホーム画面表示 profile なのか、対象棚表示可能 profile なのか、候補集合を持つ profile なのかを決める。ここで、介入後の結果で分母を決めないよう注意する。
- 期間を決める。
推薦の効果は即時に出るものもあれば、数日後に出るものもある。例えば、作品詳細クリックは即時メトリクスだが、25% 以上視聴ユニークシリーズ数や再訪問率は観測期間が必要である。
- ガードレールを決める。
短期的な OEC 改善のために、レイテンシ、継続率 proxy、TVOD 収益、安全性、多様性などを壊していないか確認する。
この流れを踏むことで、実験結果が出たときに「勝った」「負けた」だけでなく、「どの仮説が支持され、どの前提が怪しいか」を議論できる。
この節から得られる実務上の教訓
この節から得られる最も重要な教訓は、 実験前の言語化が、実験後の解釈を決める ということである。
クーポン入力欄の例では、単に「クーポン欄を追加する」ではなく、「購入確認ページにクーポンコード入力欄を追加すると、購入プロセスを開始するユーザーの 1 ユーザー当たり収益が低下する」という形まで仮説を具体化した。この具体化によって、分母、OEC、期待方向が明確になった。
Hulu の推薦でも、同じ姿勢が必要である。推薦 ML の実験は、モデルの良し悪しだけを測っているように見えるが、実際には、表示面、ユーザー文脈、作品在庫、UI、暗黙的フィードバック、ログ定義がすべて絡む。したがって、仮説が曖昧なまま実験すると、結果が出ても解釈が難しくなる。
特に、暗黙的フィードバック中心の推薦では、ユーザーが明示的に「良かった」「悪かった」と言ってくれるわけではない。視聴したかどうか、どれだけ視聴したか、戻ってきたかどうかから、ユーザー価値を推測する必要がある。そのため、OEC と分母の設計が非常に重要である。
まとめると、この節で学ぶべきことは次の通りである。
実験は、変更案から始まるのではなく、検証したい仮説から始まる。
ファネルを使うと、介入がどのユーザーに影響するかを考えやすい。
総量メトリクスではなく、ユーザー数で正規化したメトリクスを使う必要がある。
分母が広すぎると効果が希釈される。
分母が狭すぎ、介入後の結果で選別されていると、選択バイアスが生じる。
良い仮説には、介入、対象、OEC、期間、期待方向、効く理由が含まれる。
Hulu の推薦では、暗黙的フィードバックの性質を踏まえ、25% 以上視聴、再生開始、視聴時間、再訪問、TVOD 収益などを仮説に応じて使い分ける必要がある。
この節は、統計的検定の話に入る前の土台である。どれだけ高度な分析手法を使っても、問題設定と仮説が曖昧なら、実験結果は意思決定に使いにくい。逆に、仮説、OEC、分母が明確であれば、実験結果がポジティブでもネガティブでも、プロダクト理解を前に進めることができる。