ch1-2 なぜ実験をするのか:相関・因果・信用できる実験を推薦で理解する
この節の中心テーマは、「観察データで見える相関を、そのまま因果関係として扱ってはいけない」ということである。特に、サブスクリプション型サービスや動画推薦のように、ユーザーの利用頻度、嗜好、満足度、課金継続、作品の供給状況が複雑に絡む領域では、この注意が非常に重要である。
Hulu
の動画推薦で言えば、私たちは日々、多くの観察データを見ることができる。例えば、ある推薦棚をクリックしたユーザーは継続率が高い、マイリストを使っているユーザーは解約率が低い、アニメ作品を多く視聴するユーザーは視聴日数が多い、avg_fingerprint
による内容類似推薦をよくクリックするユーザーは 25%
以上視聴シリーズ数が多い、といった関係である。
しかし、ここからすぐに「その推薦棚をもっと目立たせれば継続率が上がる」「全ユーザーにマイリスト利用を強制すれば解約率が下がる」「内容類似推薦を増やせば視聴数が増える」と結論づけるのは危険である。なぜなら、観察された差は、機能そのものの効果ではなく、もともとのユーザー属性や利用意欲の違いによって生じているかもしれないからである。
この節は、その危険を説明したうえで、ランダム化されたオンラインコントロール実験がなぜ因果効果を評価するうえで強力なのか、また、実験を実務で回すために何が必要なのかを整理している。
サブスクリプションビジネスの例が言っていること
教科書では、Netflix のようなサブスクリプション型ビジネスを例にしている。毎月 のユーザーが解約しているとする。そして、ある新機能を使っているユーザーの解約率を観察すると、 、つまり半分だったとする。
このとき、直感的には「新機能を使うと解約率が半分になる」と言いたくなる。さらに踏み込んで、「この機能をもっと見つけやすくすれば、より多くのユーザーが使い、解約が大きく減る」と主張したくなる。
しかし、この結論は正しくない。観察データだけでは、その機能が解約を減らしたのか、それとも解約しにくいユーザーがその機能を使っていただけなのかを区別できないからである。
Hulu の例で置き換えると、次のような状況である。
「マイリストを使っているユーザーは解約率が低い」
「お気に入りジャンルを設定しているユーザーは視聴日数が多い」
「推薦棚から 25% 以上視聴に至ったユーザーは翌月も継続しやすい」
「検索をよく使うユーザーは視聴シリーズ数が多い」
これらはすべて、機能が良い可能性を示唆する。しかし同時に、もともと Hulu をよく使うユーザーほど、マイリストも検索も推薦棚も多く使い、しかも解約しにくい、というだけかもしれない。
このように、機能利用と解約率のあいだに相関があっても、それだけでは因果関係は分からない。
相関と因果の違い
相関とは、2 つの変数が一緒に動く傾向のことである。例えば、ある機能を使ったユーザーほど解約率が低いなら、「機能利用」と「解約率の低さ」には相関がある。
一方、因果とは、一方を変えると他方が変わるという関係である。例えば、「機能をユーザーに使わせることで、そのユーザーの解約確率が下がる」なら、機能利用は解約低下の原因である。
ここで重要なのは、相関があっても因果があるとは限らないことである。相関には少なくとも次の 3 パターンがあり得る。
機能利用が解約率を下げている。
解約しにくいヘビーユーザーが機能をよく使っている。
別の要因、例えば利用頻度や作品嗜好が、機能利用と解約率の両方を生んでいる。
教科書の Office 365 の例は、3 つ目のパターンである。クラッシュやエラーメッセージを経験したユーザーの方が解約率が低かったとしても、「クラッシュさせれば解約が減る」とはならない。ヘビーユーザーほど Office 365 を長時間使うため、エラーにもクラッシュにも遭遇しやすい。そして、ヘビーユーザーほど製品価値を感じているため、解約しにくい。つまり、「使用量」がクラッシュ経験と低解約率の両方を引き起こしている。
Hulu でも、ほぼ同じ構造が起こり得る。
例えば、「再生エラーを経験したユーザーの方が解約率が低い」という観察結果があったとする。これは一見すると奇妙である。しかし、ヘビーユーザーほど長時間視聴し、いろいろな作品を再生し、複数デバイスを使うため、再生エラーに遭遇する確率も高い。一方で、ヘビーユーザーは Hulu に価値を感じているため解約しにくい。したがって、再生エラーと低解約率が相関していても、再生エラーが解約率を下げているわけではない。
このような「第 3 の要因」は交絡因子と呼ばれる。
交絡を数値例で理解する
具体的な数値で考える。Hulu で「マイリスト機能を使ったユーザーは解約率が低い」という観察データがあったとする。
| グループ | ユーザー数 | 解約者数 | 解約率 |
|---|---|---|---|
| マイリストを使った | 10,000 | 200 | 2.0% |
| マイリストを使っていない | 90,000 | 5,400 | 6.0% |
この表だけを見ると、マイリスト利用者の解約率は 、非利用者は である。差は ポイントであり、相対的には次のように見える。
つまり、「マイリスト利用者は解約率が約 67% 低い」と言えてしまう。しかし、ここでユーザーをライトユーザーとヘビーユーザーに分けると、話が変わるかもしれない。
| 利用頻度 | マイリスト利用 | ユーザー数 | 解約者数 | 解約率 |
|---|---|---|---|---|
| ヘビー | 使った | 8,000 | 120 | 1.5% |
| ヘビー | 使っていない | 12,000 | 240 | 2.0% |
| ライト | 使った | 2,000 | 80 | 4.0% |
| ライト | 使っていない | 78,000 | 5,160 | 6.6% |
この分解を見ると、マイリスト利用者にはヘビーユーザーが多い。ヘビーユーザーはもともと解約率が低いため、単純比較ではマイリストの効果が過大に見える。もちろん、この分解後でもマイリスト利用者の方が解約率は低いが、それでも「マイリストを使わせれば解約率がこの分だけ下がる」とは言えない。ヘビーユーザーの中でも、さらに作品探索意欲が高い人がマイリストを使っているだけかもしれないからである。
これが観察データの難しさである。ログを細かく切って調整しても、未観測の交絡が残る可能性がある。例えば、ユーザーの可処分時間、家族構成、好きな作品の配信状況、競合サービスの利用、価格感度などはログだけでは完全に分からない。
ランダム化実験は何を解決するのか
ランダム化実験では、ユーザーを Control と Treatment
にランダムに割り当てる。例えば、Hulu の profile_id
を使って、50% のプロフィールには従来の推薦体験を出し、残り 50%
には新しい推薦体験を出す。
ランダム化の力は、観測できる属性だけでなく、観測できない属性も平均的に両群へ均等に分かれる点にある。もちろん、完全に同じになるわけではない。しかし、十分なサンプルサイズがあれば、利用頻度、ジャンル嗜好、デバイス、視聴時間帯、作品探索意欲、継続意欲などが、平均的には Control と Treatment に似た分布で入る。
すると、実験期間中のメトリクス差を、介入の効果として解釈しやすくなる。
たとえば、Hulu で新しい推薦モデルを 50:50 で割り当て、14 日間の 25% 以上視聴ユニークシリーズ数を比較したとする。
| 実験群 | profile 数 | 1 profile あたり 25% 以上視聴シリーズ数 |
|---|---|---|
| Control | 100,000 | 3.20 |
| Treatment | 100,000 | 3.28 |
このとき、平均差は次のようになる。
相対リフトは次のようになる。
この差は、単なる「新しい推薦を使った人」と「使わなかった人」の観察比較ではない。実験前にランダムに割り当てた 2 群の比較である。そのため、「Treatment の推薦体験が、平均的に 1 profile あたり 0.08 本の 25% 以上視聴シリーズ増加をもたらした」と解釈しやすい。
ただし、ここでも注意が必要である。ランダム化しただけで常に信用できるわけではない。ログ欠損、割当バグ、SRM、Treatment だけのクラッシュ、片方の群だけへのキャッシュ不具合、複数実験の干渉などがあると、結果の信用性は落ちる。この節が「信用性」を強調しているのはそのためである。
エビデンスの階層
教科書は、医学分野で使われてきたエビデンスの階層を紹介している。これは、どの種類の証拠が因果関係を主張するうえで強いかを整理したものである。
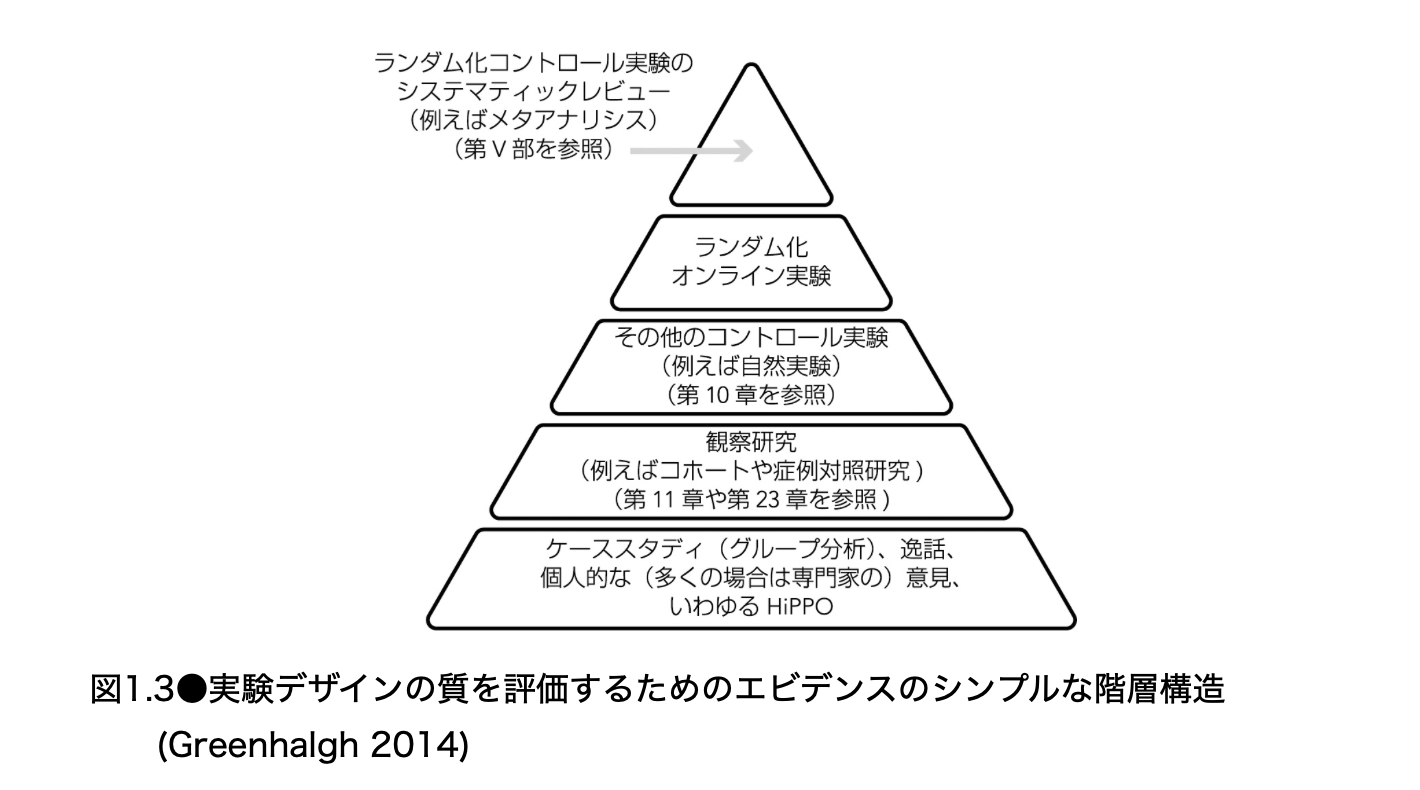
図の下の方には、ケーススタディ、逸話、個人的な意見、いわゆる HiPPO がある。HiPPO とは Highest Paid Person’s Opinion の略であり、最も報酬が高い人、つまり組織内で強い権限を持つ人の意見を指す。これらは仮説作りには有用である。例えば、経験豊富な PM や編集担当者が「このジャンル棚はもっと上に出すべきだ」と感じることは、実験案の出発点として重要である。
しかし、それだけでは因果効果の証拠としては弱い。なぜなら、人間は成功例を覚えやすく、失敗例を忘れやすく、また自分の仮説に合うデータを見つけやすいからである。
その上に観察研究がある。Hulu
のログ分析や、unique_viewed_series
を使った視聴行動分析は、多くの場合ここに入る。観察研究は非常に有用である。ユーザーの行動を理解し、仮説を作り、実験の対象を絞るためには不可欠である。しかし、観察研究だけでは交絡を完全には排除しにくい。
さらに上に、ランダム化オンライン実験がある。これは、ユーザーをランダムに割り当て、同時期に Control と Treatment を比較するため、因果関係を評価しやすい。
最上位に近いところに、ランダム化コントロール実験の系統的レビューやメタアナリシスがある。これは、複数の実験結果を統合して、より一般化可能な結論を得る方法である。オンラインサービスでも、同じような考え方は重要である。例えば、推薦棚タイトルの変更が一度だけ勝ったとしても、別のデバイス、別の季節、別のユーザーセグメント、別の棚位置でも再現するかを確認することで、より信用度が高まる。
なぜオンラインコントロール実験は強いのか
教科書は、オンラインコントロール実験の強みを 3 つ挙げている。
第一に、因果関係を高い確率で確立する最高の科学的方法である。これは、ランダム化によって交絡を平均的に取り除けるからである。
第二に、小さな変化を検出できる。大規模なオンラインサービスでは、ユーザー数が多いため、1% 未満の小さな変化でも統計的に検出できることがある。Hulu のような動画配信でも、十分なプロフィール数と安定したログがあれば、推薦経由の 25% 以上視聴率や視聴日数の小さな差を検出できる可能性がある。
第三に、予期しない悪影響を検出できる。これは推薦 ML では非常に重要である。新しいモデルは、主指標だけを見ると良く見えても、別の場所に悪影響を出すことがある。
例えば、次のような副作用があり得る。
推薦棚のクリック率は上がったが、検索利用が減り、ユーザーの能動的探索が弱くなる。
25% 以上視聴シリーズ数は増えたが、同じ人気作品への集中が強まり、カタログの多様な消費が減る。
短尺作品の視聴開始が増えたためメトリクスは上がったが、長尺映画の満足視聴が減る。
モデル推論が重くなり、トップページのレイテンシが悪化する。
一部のジャンルやキッズプロフィールで不適切な推薦が増える。
したがって、オンライン実験は「良い変化を見つける」だけでなく、「悪い変化を全体展開前に止める」ための安全装置でもある。
有益なコントロール実験に必要なもの
教科書は、有益なコントロール実験を円滑に実行するために必要な要素を 4 つ挙げている。Hulu の推薦開発に合わせて解釈すると、次のようになる。
1. 実験単位があり、干渉が少ないこと
実験単位とは、Control や Treatment へ割り当てる単位である。Hulu
の推薦では、一般には profile_id
が候補になる。なぜなら、視聴履歴や推薦体験は profile
単位で管理されることが多いからである。
ただし、実験単位同士が互いに影響しない、または影響が小さいことが必要である。これを干渉が少ないと言う。
例えば、同じ household の中に複数プロフィールがある場合を考える。親プロフィールが Treatment に入り、キッズプロフィールが Control に入ったとする。もし家族で同じテレビ画面を見ながら作品を選ぶなら、親プロフィールの推薦で見つけた作品がキッズプロフィールの視聴にも影響するかもしれない。この場合、profile 単位の独立性は完全ではない。
また、ランキング実験で「人気ランキング」をユーザー行動からリアルタイム更新している場合、Treatment ユーザーの視聴がランキング全体を変え、Control ユーザーの体験にも影響する可能性がある。このような場合も干渉が起きる。
干渉が強い場合、ユーザー単位の A/B テストでは因果効果を過小評価または過大評価する可能性がある。したがって、実験設計時には、profile 単位でよいのか、account 単位にすべきか、地域やクラスタ単位にすべきかを考える必要がある。
2. 十分な実験単位があること
実験では、十分なユーザー数が必要である。サンプルサイズが小さいと、偶然のばらつきが大きくなり、小さな効果を検出できない。
直感的には、1,000 人で平均視聴本数を比べるより、100,000 人で比べた方が、平均差を安定して推定できる。教科書が「何千もの実験単位」を推奨しているのはそのためである。
簡単な例で考える。Hulu で、1 profile あたりの 14 日間の 25% 以上視聴シリーズ数を OEC とする。Control と Treatment の標準偏差がどちらも 程度だと仮定する。各群の profile 数を とすると、平均差の標準誤差は概算で次のようになる。
各群 なら、標準誤差は次の通りである。
各群 なら、標準誤差は次の通りである。
つまり、サンプルサイズが 100 倍になると、標準誤差は 10 分の 1 になる。これは、小さなリフトを検出しやすくなることを意味する。
例えば、Treatment が平均を から に上げる、つまり差が の場合を考える。各群 では、差 は標準誤差 より小さく、偶然と区別しにくい。一方、各群 では、差 は標準誤差 の約 4.47 倍であり、かなり検出しやすい。
このように、実験感度はユーザー数に強く依存する。
3. 主要メトリクス、理想的には OEC が合意されていること
実験では、何を成功とみなすかを事前に決めておく必要がある。これが OEC である。Hulu の推薦では、候補として次のような指標が考えられる。
1 profile あたりの 25% 以上視聴ユニークシリーズ数。
推薦経由の 25% 以上視聴率。
実験期間中のアクティブ視聴日数。
翌週再訪率や継続 proxy。
長期価値の proxy としての複数日視聴、探索成功、満足視聴など。
ただし、OEC は短期間で測定可能でありながら、長期目標とつながっている必要がある。このバランスが難しい。
例えば、短期の「再生開始数」は測りやすい。しかし、再生開始だけを最大化すると、短い作品や釣りやすい作品ばかりが上位に出るかもしれない。逆に「解約率」は事業上重要だが、短期間の推薦実験では変化を検出しにくいかもしれない。そこで、25% 以上視聴、複数日視聴、翌週再訪などを長期価値の proxy として使うことがある。
ここで重要なのは、OEC とガードレールを分けることである。例えば、OEC を「推薦経由の 25% 以上視聴シリーズ数」とするなら、ガードレールとして次を同時に見る必要がある。
トップページ表示レイテンシ。
再生開始失敗率。
アプリクラッシュ率。
短時間離脱率。
キッズプロフィールでの不適切推薦率。
同一作品や同一ジャンルへの過集中。
OEC が上がっても、ガードレールが悪化するなら、プロダクトとしては成功とは言えない。
4. 変更が容易であること
コントロール実験は、変更を作って、対象ユーザーを限定して出し、ログを見て、必要なら戻せることが前提である。ソフトウェアサービスは、物理的なハードウェアや航空機制御システムに比べると変更しやすい。そのため、オンラインサービスは実験に向いている。
Hulu の推薦では、サーバーサイドの推薦モデルやランキングロジックであれば、比較的実験しやすい。例えば、候補生成の混合比率、ランキングの特徴量、棚の並び順、既視聴除外の閾値、公開終了作品のブーストなどは、サーバー側の設定やモデルバージョンで切り替えやすい。
一方で、クライアントアプリの UI 変更は、デバイスやアプリバージョンによって展開が遅れることがある。テレビアプリ、スマートフォンアプリ、Web で挙動が違う場合もある。そのため、実験のしやすさは「ソフトウェアだから簡単」と一括りにはできない。
実験しやすい設計にするには、次のような準備が必要である。
実験 ID と Variant をログに必ず残す。
推薦露出、クリック、再生開始、25% 以上視聴、完走、離脱を結合できるようにする。
サーバー側でモデルや設定を切り替えられるようにする。
問題があればすぐ Control へ戻せるようにする。
小さな割合からランプアップできるようにする。
このような基盤がないと、実験は毎回手作業になり、信用できる比較が難しくなる。
コントロール実験ができない場合もある
教科書は、すべての意思決定をコントロール実験で行えるわけではないとも述べている。例えば、M&A は A/B テストできない。企業を買収した世界と買収しなかった世界を、同じ会社で同時にランダムに比較することはできないからである。
Hulu の推薦でも、完全な A/B テストが難しい意思決定はある。
大型コンテンツの独占配信権を獲得するかどうか。
料金プランを大きく変更するかどうか。
ブランド全体の UI 方針を変えるかどうか。
作品カタログの契約構成を大きく変えるかどうか。
長期的な推薦基盤刷新に投資するかどうか。
このような場合は、観察研究、シミュレーション、ユーザー調査、定性インタビュー、準実験、過去事例分析などを組み合わせる必要がある。ただし、コントロール実験が実行可能な領域では、それが最も信用度の高い評価方法になりやすい。つまり、「何でも A/B テストすべき」ではなく、「A/B テストできるものを、信用できる形で A/B テストするべき」なのである。
原則 1:データに基づいた意思決定と OEC の公式化
教科書の原則の第一は、組織がデータに基づいた意思決定を行いたいと考えており、OEC を公式化していることである。
ここで重要なのは、「データを見る」だけではデータ駆動ではないという点である。多くの組織はダッシュボードを持っている。しかし、意思決定の前に何を成功指標とするかを決めず、実験後に都合のよい数字を探すなら、それはデータ駆動ではなく、データを使った後付けである。
Hulu の推薦実験で、次のような状況を考える。
Treatment は推薦クリック率を上げた。
しかし 25% 以上視聴率は変わらなかった。
視聴開始後 5 分未満の離脱は増えた。
トップページのレイテンシも少し悪化した。
このとき、事前に OEC が決まっていないと、「クリック率が上がったから勝ち」とも、「視聴率が変わらないから中立」とも、「離脱が増えたから負け」とも言えてしまう。これでは意思決定がぶれる。
したがって、実験前に、例えば次のように決めておく必要がある。
主 OEC は、推薦経由の 25% 以上視聴ユニークシリーズ数である。
レイテンシ、クラッシュ率、再生開始失敗率、短時間離脱率はガードレールである。
OEC が統計的にも実務的にも改善し、重大なガードレール悪化がない場合のみランプアップする。
このように決めておくことで、実験後の解釈が透明になる。
原則 2:インフラストラクチャとテストへ投資する
第二の原則は、コントロール実験を実行し、その結果が信用できることを保証するために、インフラストラクチャとテストへ投資することである。
オンライン実験では、数字を出すだけなら簡単である。しかし、信用できる数字を出すのは難しい。なぜなら、次のような落とし穴があるからである。
実験割当が 50:50 のはずなのに、実際には 52:48 になっている。
Treatment だけログ送信が欠損している。
一部デバイスで Treatment の推薦棚が表示されていない。
実験 ID が再生ログに引き継がれていない。
同じ profile が複数 Variant に入っている。
別の実験と干渉している。
ログのタイムゾーンや集計期間がずれている。
Hulu の unique_viewed_series は
last_viewing_date を JST の日付として持つ。実験期間を UTC
で切るのか JST で切るのか、公開開始・終了時刻をどう扱うのか、TVOD と
SVOD を同じ OEC
に入れるのか、ライブ作品を含めるのか、といった定義が揺れると、分析結果も揺れる。
そのため、実験基盤には少なくとも次が必要である。
安定したランダム割当。
実験 ID と Variant の一貫したログ記録。
露出、クリック、再生、25% 以上視聴を結合できるデータモデル。
SRM やログ欠損を検知する自動チェック。
ダッシュボードと分析テンプレート。
ランプアップとロールバックの仕組み。
この投資は地味だが、実験の信用性を支える。信用できない実験基盤で大量に実験しても、誤った意思決定を高速化するだけである。
原則 3:アイデアの価値を評価するのが苦手だと認識する
第三の原則は、組織が「自分たちはアイデアの価値を評価するのが苦手である」と認識することである。これは非常に実務的な原則である。
チームが機能を作るとき、その機能は有用だと信じられている。誰も悪くするために開発しているわけではない。しかし、教科書が引用しているように、多くの企業では、実験で主要メトリクスを改善するアイデアは一部にすぎない。Microsoft では約 3 分の 1、Bing や Google のように最適化が進んだ領域では 10% から 20% 程度という例が紹介されている。
Hulu の推薦でも、これは自然なことである。例えば、次のような仮説はどれももっともらしい。
視聴済み作品に似た作品を増やせば、ユーザーは選びやすくなる。
多様性を高めれば、新しい発見が増える。
公開終了が近い作品を上げれば、見逃しが減る。
人気作品を強めれば、視聴開始率が上がる。
ニッチ作品を少し混ぜれば、ロングテール消費が増える。
しかし、これらは互いに衝突することもある。似た作品を増やすと新鮮味が減るかもしれない。多様性を高めると短期視聴率が下がるかもしれない。公開終了作品を上げると、ユーザーが本当に今見たい作品が下がるかもしれない。人気作品を強めると、すでに知っている作品ばかりになり、探索体験が悪化するかもしれない。
つまり、事前に勝ち負けを正確に当てるのは難しい。だからこそ、実験が必要なのである。
データ駆動とデータインフォームド
教科書では、データ駆動とデータインフォームドをほぼ同義に扱うと述べている。ただし、ここには大事なニュアンスがある。
データ駆動とは、データだけで機械的に意思決定するという意味ではない。実験結果、ユーザー調査、プロダクト戦略、法務・倫理、ブランド価値、運用コスト、技術的負債など、複数の情報を使って意思決定するということである。
例えば、ある推薦実験で 25% 以上視聴シリーズ数が 0.5% 上がったとする。しかし、その変更はモデル構成を非常に複雑にし、運用コストを大きく上げ、説明可能性を下げるかもしれない。この場合、実験が勝ったから即採用とは限らない。
逆に、短期 OEC は中立でも、長期戦略上重要な探索体験や新規ジャンル発見を改善する施策なら、追加実験や長期観察を行う価値があるかもしれない。
したがって、データは意思決定を置き換えるものではなく、意思決定の質を上げるための材料である。ただし、データを使うなら、後付けではなく、事前に OEC と判断基準を定義し、信用できる形で測る必要がある。
Hulu 推薦における実験設計の実務チェックリスト
この節の内容を Hulu 推薦の実務に落とすと、実験前に少なくとも次を確認したい。
実験の仮説は何か。例として、「内容類似候補を追加すると、視聴済み作品に近い未視聴作品を見つけやすくなり、25% 以上視聴シリーズ数が増える」がある。
ランダム化単位は何か。基本は
profile_idか、干渉が懸念されるなら account 単位も検討する。Control と Treatment の違いは何か。モデル、候補生成、ランキング、UI 表示のどれが変わるのかを明確にする。
OEC は何か。例として、推薦経由の 25% 以上視聴ユニークシリーズ数がある。
ガードレールは何か。レイテンシ、クラッシュ率、再生失敗率、短時間離脱、キッズ安全性などを確認する。
サンプルサイズと実験期間は十分か。小さな効果を検出するには十分な profile 数が必要である。
ログは信用できるか。露出、クリック、再生、25% 以上視聴、実験 ID、Variant が結合できる必要がある。
異常検知はあるか。SRM、ログ欠損、極端なリフト、デバイス別の異常を確認する。
意思決定基準は事前に決まっているか。実験後に都合のよい指標を探さないようにする。
まとめ
この節が伝えている最重要ポイントは、相関は因果ではないということである。サブスクリプションサービスでは、機能利用者の解約率が低いという観察結果は頻繁に見つかる。しかし、それは機能が解約を下げたからではなく、もともと利用意欲の高いユーザーがその機能を使っているだけかもしれない。
Hulu の動画推薦でも、マイリスト利用、検索利用、推薦棚クリック、25% 以上視聴、視聴日数、継続率は複雑に絡む。観察ログは仮説作りには非常に重要だが、因果効果を確認するにはランダム化されたオンラインコントロール実験が最も信用できる方法になりやすい。
ただし、ランダム化すればそれだけで十分というわけではない。信用できる実験には、適切な実験単位、十分なサンプルサイズ、合意された OEC、変更しやすいソフトウェア設計、信頼できるログ、SRM やログ欠損を検知する仕組みが必要である。
そして組織としては、OEC を公式化し、実験インフラへ投資し、自分たちはアイデアの価値を事前に評価するのが苦手であると認める必要がある。この謙虚さがあるからこそ、A/B テストは単なる分析手法ではなく、プロダクト改善を継続するための学習システムになるのである。